tags search: trucchi
Sbloccare ed installare l'ultima MIUI in italiano su Xiaomi Redmi 4 PRO (forse vale anche per altri modelli)
NOTE:
Questa guida nasce dall’esperienza e da altre guide trovate in rete, serve per sbloccare telefoni XIAOMI con versioni farlocche di MIUI, come la 8.0.4.0 LXKCNMA che avevo io, che non sono aggiornabili e sono spesso malfunzionanti (non mi stupirei se contenessero dei malware, ma non ne ho idea). Se tu avessi già una versione ufficiale di MIUI installata sul telefono, puoi seguire la guida partendo dalla sezione "sblocchiamo il telefono".
Questa procedura è quella che ho seguito io, passo dopo passo, per sbloccare il mio Redmi 4 PRO. Ha funzionato senza problemi e non vedo perché non dovrebbe farlo anche con te, ma non mi assumo responsabilità di alcun tipo nel caso qualcosa non andasse per il verso giusto ![]() .
.
PREPARAZIONE:
-
Metti in carica il telefono ed attendi che arrivi al 100%. Aspettare un'ora in più e partire con il telefono carico al 100% è molto meglio rispetto al rischio di trovarsi un fermacarte perché il telefono si è scaricato totalmente durante uno dei passaggi
-
Nel frattempo, scarica la rom fastboot in versione developer (il formato del file deve essere .tgz e non .zip). Scompatta il file da qualche parte, facendo attenzione che nel percorso non ci siano spazi (es: “redmi” va bene, “redmi rom fastboot” no): http://en.miui.com/a-234.html
-
Scarica Mi Flash (beta): http://c.mi.com/in/thread-2434-1-1.html
-
Scarica i driver PDAnet, ricordandosi di sovrascrivere eventuali driver che secondo l’installer sono già presenti: http://pdanet.co/bin/PdaNetA4197.exe)
-
Installa Mi Unlock tool: http://en.miui.com/unlock/
-
Scarica minimal Adb/Fastboot: https://www.androidfilehost.com/?fid=457095661767103465
-
Scarica una recovery TRWP: https://www.androidfilehost.com/?fid=457095661767117508
-
Scarica l’ultima versione della miui da xiaomi.eu oppure miui.it (guida alla scelta)
-
OPZIONALE: Scarica SuperSU, pacchetto “Recovery Flashable.zip” se vuoi avere i permessi di root: http://www.supersu.com/download#zip
PROCEDURA PER INSTALLARE UNA ROM UFFICIALE:
-
Nelle impostazioni del telefono / informazioni, clicca diverse volte sulla versione della miui finché non risponde che sei un developer.
-
Cerca developer options in Additional Settings, abilita USB debugging e OEM unlocking.
-
Collega il telefono al PC.
-
Installa i drivers PDAnet, consentendo tutto ciò che viene richiesto.
-
Apri una console nella directory in cui è salvato adb/fastboot, poi digita “adb devices”. Se tutto va bene, questo comando dovrebbe mostrare un codice.
-
Digita “adb reboot edl”.
-
Apri Mi Flash, seleziona la cartella relativa al file .tgz che hai scompattato precedentemente, e clicca il bottone “refresh”.
-
La lista dovrebe mostrare il tuo telefono e dirti che è collegato ad una porta COMx.
-
Clicca su Flash, e aspetta che finisca il tutto. Se non dovesse funzionare prova con un’altra porta usb o prova a ripetere le ultime operazioni, da “adb reboot edl”.
-
-
Quando il flash è terminato, tieni premuto il tasto di accensione ed il telefono si accenderà. Ci vorranno diversi minuti quindi mettiti comodo.
-
Connetti la rete wifi, ma salta pure gli altri passaggi (incluso il MI Account che per ora non serve).
-
Come prima, attiva la modalità developer, abilita USB debugging e OEM unlocking. Sotto la voce OEM unlocking è presente un’opzione per collegare il MI Account. Fallo da qua ed ignora eventuali errori (a meno che non sia la password errata :)).
-
Copia il file .zip della miui nella cartella principale della memoria del telefono.
-
OPZIONALE: Copia anche il file di SuperSU nella stessa cartella.
SBLOCCHIAMO IL TELEFONO
-
Spegni il telefono e riavvialo in modalità fastboot (VOL- e tasto di accensione)
-
Sul pc, apri Mi Unlock Tool, inserisci le tue credenziali e segui i passaggi per sbloccare il telefono. Nel caso in cui ti fosse capitato seguendo altre guide, ora non dovrebbe più inchiodarsi al 50%.
INSTALLIAMO LA RECOVERY TWRP
-
Sul pc, torna sul prompt dei comandi nella cartella di adb/fastboot, e digita “adb devices”. Dai il consenso per eventuali popup che dovessero presentarsi.
-
Riavvia il telefono in modalità fastboot (VOL- e tasto di accensione)
-
Sul pc, dal prompt dei comandi digita “fastboot flash recovery recovery.img”. Questa operazione dovrebbe richiedere pochi secondi. Digita poi “fastboot boot recovery.img”
-
Il telefono si riavvierà con la nuova recovery TWRP. In cinese.
-
Se non conosci il cinese, limitati a flaggare la checkbox e fare lo slide sullo slider, poi clicca sul penultimo elemento in basso a destra. Nel menu in alto dovrebbe comparire un globo, cliccando quello puoi cambiare la lingua con quella che vuoi (consiglierei l’inglese, visto che le prossime istruzioni saranno in inglese)
INSTALLIAMO LA NOSTRA NUOVA ROM PREFERITA
-
Torna al menu principale di TWRP e clicca su “Wipe”. Conferma l’operazione con uno slide sullo slider.
-
Torna al menu principale e clicca su “Install”. Seleziona la rom che hai scaricato prima e seleziona “Flash”.
-
OPZIONALE: sempre dal menu Install, seleziona il pacchetto du SuperSU per avere il telefono con i permessi di root
-
Fai un wipe cache/dalvik
-
spegni il telefono tenendo premuto il tasto di accensione per parecchi secondi
-
Preparati ad aspettare circa 10 minuti per il primo avvio
FINE!
Stampare un PDF per ogni file LibreOffice in una directory
Questa mattina avevo necessità di creare un file PDF per ogni file LibreOffice CALC presente in una directory. È una cosa che devo fare, periodicamente, ed aprire i singoli file è un'operazione noiosa, soprattutto quando iniziano ad esserci decine di documenti da convertire.
Per fortuna uso linux :) ed è semplice creare uno script che mi permetta di effettuare quest'operazione da linea di comando... ma ancora non mi è sufficiente, vorrei poterlo fare direttamente da Nautilus.
Detto fatto
Prima di tutto è necessario creare un nuovo file nella directory ~/.local/share/nautilus/scripts, io l'ho chiamato "Crea PDF da documento LibreOffice" (senza estensione perché anche quest'ultima verrebbe mostrata nel menu contestuale di Nautilus). Dentro ci ho messo questo:
#!/usr/bin/perl -w
# By Emanuele "ToX" Toscano
use strict;
my @files = split("\n", $ENV{NAUTILUS_SCRIPT_SELECTED_FILE_PATHS});
foreach my $file (@files)
{
if ( -f $file )
{
system("libreoffice --headless --convert-to pdf --outdir ./pdf/ '$file'");
shift;
}
}
Ho salvato il file, l'ho reso eseguibile, ho selezionato un po' di files e cliccato tasto destro... vedo che lo script "Crea PDF da documento LibreOffic", lo lancio e... inaspettatamente ha funzionato tutto al primo colpo :) Mi ha creato tanti file PDF quanti erano i file selezionati, e li ha salvati all'interno di una sottocartella "pdf".
Facile, no? :)
Affiancare più video con FFMPEG
Oggi ho avuto necessità di fare una cosa diversa dal solito: niente programmazione, ma ho dovuto realizzare un video che fosse il risultato di quattro video, affiancati due a due (2 video sopra, 2 video sotto).
Realizzare qualcosa del genere può sembrare difficile, ma con gli strumenti giusti (ed un minimo di dimestichezza con la shell) si tratta di una cosa veramente semplice. Dopo un po' di ricerche e di tentativi, ecco il risultato:
#!/bin/bash ffmpeg -i 1.avi -vf "movie=2.avi [in1]; [in]pad=500:210:color=white[in0]; [in0][in1] overlay=250:0 [out]" -crf 5 -b:v 8M out1.avi ffmpeg -i 3.avi -vf "movie=4.avi [in1]; [in]pad=500:236:color=white[in0]; [in0][in1] overlay=230:15 [out]" -crf 5 -b:v 8M out2.avi ffmpeg -i out1.avi -vf "movie=out2.avi [in1]; [in]pad=500:446:color=white[in0]; [in0][in1] overlay=0:216 [out]" -crf 5 -b:v 8M out.avi rm out1.avi rm out2.avi
La prima riga affianca i primi due video (1.avi e 2.avi) in un file temporaneo chiamato out1.avi. Le dimensioni del file risultante sono specificate nell'istruzione pad=500:210, che si occupa di "creare" lo spazio in cui inserire il secondo video, impostando uno sfondo bianco fra un video e l'altro (ho voluto lasciare qualche pixel di distanza fra i due video). L'istruzione overlay=250:0 invece inserisce il secondo video nello spazio creato in precedenza, a 250px da sinistra e 0 dall'alto.
I parametri finali (-crf 5 -b:v 8M) sono necessari per mantenere una qualità decente nel file risultante. Non conosco precisamente il significato di questi parametri, so solo che mi hanno permesso di mantenere inalterata la qualità iniziale dei singoli video. Per maggiori informazioni, consulta il manuale di ffmpeg.
La seconda riga fa la stessa cosa con i file 3.avi e 4.avi, creando un file out2.avi.
La terza riga prende out1.avi e out2.avi e li posiziona uno sopra l'altro. Le istruzioni sono simili, cambiano solamente il padding e l'overlay.
Fatto questo elimino i file temporanei et voilà, il file out.avi contiene i 4 video, affiancati.
Facile, no?
Disattivare l'autocomplete su chrome (ed altri browser)
Disattivare l'autocomplete per username e password dovrebbe essere una questione semplice, normalmente si tratta solamente di un
autocomplete='off'
da implementare a livello di singolo campo e/o di form. Purtroppo chrome ha deciso di fare a modo suo, e quell'attributo non è sufficiente. L'autocomplete lo vuole usare a tutti i costi, e se trova un campo di tipo password, lui presume che quello precedente sia lo username.
Disattivarlo è semplice, ma è un workaround degno di un Internet Explorer qualunque. Per raggiungere questo obiettivo, è sufficiente mettere -prima dei veri campi username e password- due campi nascosti e fasulli... chrome li vede, pensa di dover usare l'autocomplete lì e si lascia fregare.
Per farla breve, appena dopo l'apertura del form metti qualcosa del genere:
<!-- campi fasulli nascosti, per fregare chrome con l'autocomplete --> <input style="display:none" type="text" name="fakeusernameremembered"/> <input style="display:none" type="password" name="fakepasswordremembered"/>
Et voilà.
Ridicolo, no?
Pre-push GIT Hook - Aggiornare un sito remoto ed il database tramite SSH con un git push
In questi giorni mi è capitato di dover lavorare su un nuovo progetto e di dover caricare le modifiche online man mano che il procedimento andava avanti... siccome farlo manualmente è un'operazione noiosa e ad alto rischio di errori (collegati all'ftp, carica le modifiche, elimina i files non più utilizzati...) ho pensato di sfruttare la potenza e la velocità di rsync agli hooks di GIT per effettuare questa operazione in automatico, ogni volta che faccio un push.
Puoi vedere il gist a questo indirizzo: Gist
Il funzionamento è molto semplice, eccolo riassunto:
#!/bin/sh ############## ## CONFIGURATION ############## # remote access sshUser="" sshPass="" remoteServer="192.168.1.1" remotePath="/var/www/production" # local database localDbName="myapp" # remote database remoteDdbUser="root" remoteDbPass="" remoteDbName="myapp" ############## ## WORKFLOW ############## # create a database backup and add it to the last commit (amend) mysqldump -uroot --skip-extended-insert $localDbName > database.sql git add database.sql git commit --amend --no-edit # since you can't force the password for SSH, echo it here as a hint (don't do this for critical projects! :)) echo When prompted, please insert this password: $sshPass # update all the files through rsync echo echo Updating files... rsync -rzhe ssh --delete --filter=':- .gitignore' ./ $sshUser@$remoteServer:$remotePath # update the database echo echo Updating database... cat database.sql | ssh $sshUser@$remoteServer "mysql -u$remoteDdbUser -p$remoteDbPass $remoteDbName" # and you're done! exit 0
Facile, no?
Effettuare il deploy di un'applicazione Meteor.JS sul proprio server
Ho scoperto Meteor da poco e già me ne sono innamorato. Un'occhiata alla documentazione ed alle funzionalità penso sia sufficiente per capire le potenzialità di questa piattaforma quindi non intendo dilungarmi oltre. Passerò direttamente ad un aspetto successivo, cioè la pubblicazione di un'applicazione già fatta su un server raggiungibile dall'esterno, con un proprio indirizzo web (requisito necessario è avere accesso root SSH al sistema). Esistono due modi:
Metodo 1
Il primo metodo, quello più semplice e veloce, consiste nello sfruttare quello che meteor mette a disposizione cioè un hosting gratuito sui loro server, che può essere sfruttato utilizzando un sottodominio (es. ilmiosito.meteor.com) oppure, impostando i corretti parametri nel pannello di controllo del proprio hosting, con un dominio personale. Per caricare il sito è sufficiente posizionarsi nella directory di lavoro ed impartire questo comando:
meteor deploy ilmiosito.meteor.com
Et voilà. Nel giro di qualche secondo il sito è già online e funzionante a quell'indirizzo. Peccato che quell'hosting, per quanto comodo e gratuito, non sia proprio il massimo della velocità... ma niente paura c'è il
Metodo 2
Il secondo metodo consiste nell'ospitare l'applicazione su un proprio server (configurato con node.js e mongodb naturalmente). In questo caso il deploy è un decisamente più delicato e complesso, ma dopo aver sbattuto la testa in diversi modi credo di aver trovato la procedura corretta. Eccola:
Prima di tutto è necessario (o conveniente, giudicate voi in base al vostro grado di fiducia nel genere umano) configurare mongodb per non accettare le connessioni anonime. Procediamo quindi con la creazione di un utente di amministrazione su mongo:
$ mongo
MongoDB shell version: 2.6.5
​connecting to: test
> use admin
> db.createUser(
{
user: "amministratore",
pwd: "password",
roles:
[
{
role: "userAdminAnyDatabase",
db: "admin"
}
]
}
)
Fatto. Successivamente è necessario modificare il file /etc/mongodb.conf, decommentando la stringa auth=true per fare in modo che le connessioni a mongo non possano più avvenire in modo anonimo.
Fatto questo ci si ricollega a mongo con le credenziali appena inserite per creare il nuovo db:
$ mongo -u amministratore -p password --authenticationDatabase admin
> use ilmiodatabase
> db.createUser("ilmioutente", "lamiapassword")
Ok, anche questa è fatta. Abbiamo appena creato un nuovo database "ilmiodatabase" ed il relativo utente con accesso in lettura e scrittura.
Dopodiché vorremo importare il database che usavamo nella piattaforma di sviluppo, giusto? Per fare questo è sufficiente impartire questo comando (meteor deve essere avviato):
mongodump -h 127.0.0.1 --port 3001 -d meteor
Questo creerà una directory dump/meteor che contiene i files del database. Carichiamoli sul server tramite FTP o lo strumento preferito, e poi importiamoli:
mongorestore -h localhost --port 27017 -u ilmioutente -p lamiapassword -d ilmiodatabase cartella/dei/dump
Fatto? Bene, ormai ci siamo quasi. Ora passiamo ai files. Prima di tutto dobbiamo fare il build del sistema, quindi ci posizioniamo nella directory di sviluppo e diamo:
meteor build build
Questo comando creerà un pacchetto minifizzato, concatenato e quant'altro del nostro sito, mettendolo in formato compresso con tar.gz dentro la cartella "build". Ora possiamo prendere questo file, caricarlo sul server e scompattarlo. Fatto questo, è necessario installare le dipendenze di npm:
(cd programs/server && npm install)
A questo punto possiamo finalmente far partire il sito! Scherzavo :). Prima bisogna specificare i parametri di connessione. Questo passaggio è necessario ogni volta che si fa partire il server, ovviamente è possibile creare uno script di avvio per velocizzare questo passaggio:
export MONGO_URL='mongodb://ilmioutente:lamiapassword@localhost:27017/ilmiodatabase' export ROOT_URL='http://www.ilmiositoweb.ext' export PORT=3100
Ed infine...
node main.js
Et voilà! Il sito è ora raggiungibile all'indirizzo http://www.ilmiositoweb.ext:3100. Comodo vero? In effetti non molto, ma una volta capiti i passaggi non è poi una questione così complicata :)
Un'ultima cosa: probabilmente non è la scelta più comune quella di avere un dominio raggiungibile sulla porta 3100, ma è naturalmente possibile far girare il sito sulla normale porta 80 con alcuni trucchetti. Nel mio caso, avendo apache che occupa la porta 80 ho dovuto configurare un reverse proxy.
AGGIORNAMENTO
Siccome configurare un reverse proxy può non essere banale, aggiungo i passaggi che ho seguito per attivarlo (questo è molto utile in particolare se si vuole sfruttare la tecnologia del WebSocket, che con meteor è attiva di default).
Prima di tutto è necessario installare alcuni moduli di apache:
sudo a2enmod proxy proxy_http proxy_wstunnel
Poi bisogna creare un VirtualHost un po' personalizzato, che contiene la porta su cui risponde il server node ed il WebSocket:
<VirtualHost *:80 >
ServerAdmin postmaster@ilmiositoweb.ext
ServerName ilmiositoweb.ext
ServerAlias *.test.local
ServerSignature Off
ProxyRequests off
<Proxy *>
Order deny,allow
Allow from all
</Proxy>
<Location />
ProxyPass http://localhost:3101/
ProxyPassReverse http://localhost:3101/
</Location>
<IfModule mod_rewrite.c>
RewriteEngine on
RewriteCond %{HTTP:UPGRADE} ^WebSocket$ [NC]
RewriteCond %{HTTP:CONNECTION} ^Upgrade$ [NC]
RewriteRule .* ws://localhost:3101%{REQUEST_URI} [P]
</IfModule>
</VirtualHost>
Et voilà... con un riavvio del server apache dovrebbe essere tutto a posto!
AGGIORNAMENTO 2
Piccola precisazione: il metodo sopra indicato per attivare il websocket tramite proxy di apache funziona esclusivamente su apache 2.4 e successive versioni, mentre non è disponibile su apache 2.2 o precedenti. Nel caso in cui non sia possibile attivare websocket ma sia comunque necessario utilizzare il proxy potrebbe essere conveniente disattivare WS esportando questa regola prima di lanciare node:
export DISABLE_WEBSOCKETS=true
Personalizzare la shell bash quando si lavora su un progetto GIT
Per chi utilizza GIT da riga di comando può essere utile avere sottomano lo stato del proprio repository, per sapere al volo se ci sono dei file modificati mandare in stage, se c'è da farne il commit o se c'è qualcosa da pushare.

Per fortuna il file .bashrc ci viene in aiuto ed è (relativamente) semplice personalizzare la propria shell Bash secondo le nostre necessità. Nella fattispecie, ho optato per indicare in rosso fra parentesi graffe il nome del branch attivo in cui sono presenti files modificati non ancora mandati in stage, in giallo (sempre fra graffe) i files in stage di cui fare il commit, mentre in verde (fra parentesi tonde) i repository puliti, con un asterisco ad indicare se è necessario fare il push fra il repository locale e quello remoto. In azzurro, infine, i repository che contengono untracked files.
Dopo un po' di utilizzo sono soddisfatto del risultato, è comodo avere quelle informazioni a portata di mano senza dover fare git status ogni volta.
Se vuoi implementare anche tu questa modifica, segui le istruzioni che trovi qua (https://github.com/ToX82/git-bashrc).
Facile, no?
Aruba e "No input file specified."
 Lavoro nel campo dello sviluppo web da quasi un decennio ormai, eppure alcuni hosting continuano a stupirmi ogni volta che ho a che fare con loro. Uno di questi è aruba, che con il suo pannello di controllo che sembra arrivare dagli anni 90 continua a mettermi in difficoltà fin dalla prima volta che l'ho conosciuto.
Lavoro nel campo dello sviluppo web da quasi un decennio ormai, eppure alcuni hosting continuano a stupirmi ogni volta che ho a che fare con loro. Uno di questi è aruba, che con il suo pannello di controllo che sembra arrivare dagli anni 90 continua a mettermi in difficoltà fin dalla prima volta che l'ho conosciuto.
Questa volta si è trattato del sito di un cliente, online da alcuni anni, che in questi giorni ha deciso di spostare il tutto su aruba. Di solito è sufficiente trasferire file e database, modificare un file di configurazione, svuotare la cache ed il gioco è fatto ma stavolta mi sono imbattuto in un errore strano: L'home page funzionava perfettamente ma tutte le altre pagine mostravano un triste messaggio "No input file specified.", nero su bianco. Impenetrabile come la nebbia della bassa padana.
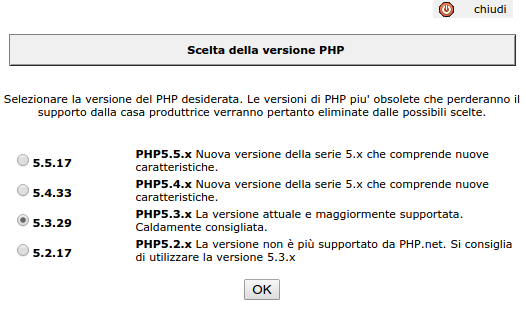
Dopo interminabili ricerche su internet, una (inutile) ri-esecuzione della copia di file e database, qualche momento di stupore nello scoprire che è "caldamente consigliata" la versione 5.3.29 di PHP ("PHP5.3.x La versione attuale e maggiormente supportata. Caldamente consigliata." il cui supporto è terminato mesi fa) e che la versione 5.4 (uscita nel 2012) è considerata la "Nuova versione della serie 5.x che comprende nuove caratteristiche", eccetera... finalmente ho capito il problema. Il file php.ini di default su aruba contiene un'istruzione cgi.fix_pathinfo = 0 che su alcuni siti (per esempio joomla, o nelle versioni vecchie di CakePHP) può dare problemi.
Per risolvere questa scocciatura è sufficiente andare nel "magnifico" pannello di controllo, cercare (navigando fra le mille finestre che aruba gentilmente ci propone) la voce Personalizzazione del file PHP.INI ed all'interno di quella nuova finestra selezionare cgi.fix_pathinfo, che imposta il relativo valore a 1.
Fatto questo, dovrebbe tornare tutto a funzionare. O almeno si spera...
Installare copy.com client (alternativa a dropbox) su linux
Installare il client di copy.com su linux è molto semplice, se sai come farlo :) Personalmente ne ho capito il funzionamento solo dopo aver fatto qualche ricerca su internet, aspettandomi chissà quale complicazione che poi... non ho trovato.
Primo passo: registrazione
Copy.com, a differenza di molti servizi simili e più famosi, è molto generoso in quanto a spazio che mette a disposizione per gli account gratuiti: si parte da 15GB di spazio ed ogni referral regala altri 5gb. Se ti va di usufruire di questo regalo (facendone uno uguale anche a me) clicca qui, altrimenti clicca sul link che ho messo all'inizio, il bottone per la registrazione è lassù in alto a destra :)
Secondo passo: installazione
L'installazione come dicevo è semplicissima, ma richiede l'utilizzo del terminale (volendo si può fare da file manager, ma perché complicarsi la vita?):
sudo su cd /opt wget https://copy.com/install/linux/Copy.tgz tar -zxf Copy.tgz rm Copy.tgz
Et voilà, l'installazione è fatta :)
Terzo passo: prima configurazione
Sempre da terminale, lanciamo il comando
/opt/copy/x86_64/CopyAgent
Questo farà partire un'interfaccia grafica che ci chiederà l'indirizzo email usato per la registrazione e la relativa password, seguito dal percorso in cui si vuole installare la cartella condivisa di Copy (di default è una cartella Copy dentro la home). Dal prossimo riavvio l'agent partirà in automatico, quindi non è necessario fare altro.
Quarto passo: usare copy
Copia un file, una directory o quello che vuoi nella cartella appena creata et voilà, al resto penserà tutto lui :)
Utilizzare l'agent da console senza l'interfaccia grafica (utile per l'utilizzo su server)
Per utilizzare l'agent da console è sufficiente lanciare l'apposito comando, al resto (come d'abitudine) penserà a tutto lui, utilizzando le impostazioni che abbiamo inserito precedentemente:
/opt/copy/x86_64/CopyConsole
Et voilà
Facile no? :)
Ottimizzare la dimensione dei PDF su linux, con un solo click
In questi giorni avevo necessità di creare uno script che mi permettesse di ottimizzare i PDF generati dal mio scanner, per ridurne le dimensioni. Inoltre, volevo poter lanciare lo script direttamente da nautilus tramite un click destro sul file.
Dopo aver vagato inutilmente per il web ho deciso di crearne uno da zero :)
Prima di tutto, ho creato un file chiamato optimizePDF.sh:
#!/bin/bash
for file in "$@"; do
echo "Processing $file";
gs -dNOPAUSE -dBATCH -sDEVICE=pdfwrite -dCompatibilityLevel=1.4 -dPDFSETTINGS=/ebook -sOutputFile=/tmp/tempfile.pdf "$file";
if [ $? -eq 0 ]; then
mv /tmp/tempfile.pdf "$file";
zenity --info --text 'File converted successfully!'
else
rm /tmp/tempfile.pdf
zenity --error --text 'Error during conversion! The original file has not been modified. Sorry!'
fi
done
Ciò che fa è semplice: nei parametri con cui lancio lo script passo il nome del file (o i nomi, se è più di un file), lui lo "passa" a ghostscript (gs) e tramite un'accurata scelta di parametri lo comprime, preservando comunque una buona qualità.
Una volta creato il file l'ho spostato in /usr/bin, in modo tale da renderlo raggiungibile da tutti gli utenti:
sudo mv optimizePDF.sh /usr/bin
Volendo è già possibile utilizzare lo script lanciandolo a mano:
$ optimizePDF.sh /path/del/file.pdf
Però io avevo necessità di lanciarlo direttamente da nautilus, così ho creato (tramite Nautilus-Actions Configuration Tool, che a voi non servirà) il pulsante da infilare nel menu contestuale (quello che compare con il click destro del mouse selezionando uno o più file PDF). Per questa funzionalità sarà sufficiente scaricare questo file ed importarlo tramite il comando
gconftool-2 --load action-2e093541-6845-426b-836b-a05d9bffcd8d.xml
Et voilà! Facile no? :)
Risolvere la lentezza mostruosa di sendmail su ubuntu
In questi giorni avevo bisogno di testare l'invio di alcune email di conferma per un applicativo scritto in PHP. Niente di particolarmente complesso, ma una volta installato il pacchetto sendmail e php-mail notavo una enorme lentezza nell'invio delle email. Parlo di 2-3 minuti di attesa, con tanto di pagina web bloccata, in attesa che la mail venisse inviata: mostruosamente troppo! Come diamine è possibile?
Indagando su san google sono finalmente riuscito a venire a capo del problema. Di default, il file /etc/hosts di ubuntu non specifica il dominio locale, che però a sendmail serve. In pratica, è necessario aggiungerlo a mano. Per fare ciò, se il file /etc/hosts di default è simile a questo:
127.0.0.1 emanuele.itoscano.com 127.0.1.1 miohost
È sufficiente modificarlo così:
127.0.0.1 emanuele.itoscano.com.localdomain emanuele.itoscano.com 127.0.1.1 emanuele.itoscano.com.localdomain miohost
Naturalmente, "miohost" corrisponde all'hostname della propria macchina. Se non sapessi qual è, per scoprirlo ci viene in aiuto questo comando, che fornirà il dato che ci serve:
sudo cat /etc/hostname
Fatto questo potrebbe essere necessario riavviare i servizi di sendmail e apache2.
Facile e veloce no? Spero che questa miniguida possa farti risparmiare un po' del tempo che io ci ho messo per venirne a capo ![]() .
.
Visualizzare il testo di una pagina durante il caricamento
Perdona il titolo nebuloso, ma non so come riassumere meglio questa piccola ma utie pillola di codice.
Come al solito parto dalla necessità: ho creato una piccola applicazione che per via dei lunghi tempi di esecuzione rende difficile capire cosa sta facendo, fino a quando non ha terminato l'ultimo script. Il che può essere ragionevole fino a quando lo script richiede pochi secondi, ma quando ne richiede alcune decine... è decisamente troppo.
Da qui la necessità di stampare sullo schermo un resoconto per ogni operazione completata, per poi fare il resoconto finale al termine del tutto. Più facile a dirsi che a farsi, probabilmente. Per me di sicuro lo era finché non mi sono imbattuto in questa piccola chicca:
function echo_live($txt) {
// inizializzazione del buffer per l'output
if (ob_get_level() == 0) ob_start();
echo $txt;
// per Chrome e Safari si deve aggiungere questa istruzione
print str_pad('',4096)."\n";
// invia il contenuto al buffer
ob_flush();
flush();
}
Queste poche righe di codice fanno proprio ciò che mi serve: stampano una stringa a video immediatamente, senza aspettare il "termine dei lavori". Figata. Quello che è più importante è che, in sostanza, invece di fare un "echo" dell'informazione che voglio mostrare a video, basta utilizzare la nuova funzione "echo_live", senza dover riscrivere pressoché nulla nel codice.
Comodo vero?
Effettuare il dump di una tabella MySQL da php
Recentemente mi è capitato di dover creare uno script PHP che effettuasse il dump di una tabella di un database MySQL e la salvasse in un file, magari con compressione gzip.
Su internet ci sono decine di risorse, qualcuna fatta a mano, qualcuna che sfrutta il (comodissimo) programma mysqldump, ma nessuno propriamente personalizzabile: a me serviva qualcosa che tirasse giù i dati, magari in una sola insert e non in duecentomila, ma che all'occorrenza mi permettesse anche di inserire le istruzioni di DROP TABLE e la seguente CREATE.
Così, sfruttando parte di script scritti da qualcun altro, me ne sono creato uno da me. Lo riporto qua, sperando che possa essere utile a qualcuno.
Clicca per vedere lo script!
Rimuovere tutti i kernel inutilizzati su debian, con un solo comando
Ecco un comodo comando che serve a cancellare, con una sola linea di codice, tutti i kernel inutilizzati sulla propria linux box:
sudo apt-get remove $(dpkg -l|egrep '^ii linux-(im|he)'|awk '{print $2}'|grep -v `uname -r`)
Con ubuntu si può fare da interfaccia grafica, da ubuntu tweak... ma così è ancora più comodo no?
Disabilitare gli errori "deprecated" delle vecchie versioni di cake su php 5.3
A volte capita di dover mettere mano a vecchi siti sviluppati su cakephp 1.2, e spesso ci si inciampa in noiosi errori "deprecated" dovuti alla differenza di versione di PHP (cakephp 1.2 era scritto per php4, pur girando anche su php5, mentre cakephp 2.0 gira solo su php5.3).
Dopo essere diventato matto per capire come nascondere quei messaggi ho trovato una soluzione che credo sia la migliore, se non altro per la comodità: aggiungere una piccola istruzione in cima al file ./index.php che spieghi a php che gli errori di quel genere deve ignorarli:
if(defined('E_DEPRECATED')) {
error_reporting(E_ALL & ~E_DEPRECATED);
}
Preparare i file .po per tradurre un sito fatto in cakephp
Recentemente mi è capitato di dover tradurre tutte le stringhe di un sito scritto in CakePHP, ma solo in inglese. Un autentico lavoraccio visto che il sito aveva una miriade di pagine e di funzionalità.
Dalla mia c'era il fatto, e chi usa CakePHP lo sa, che gli strumenti che questo fantasmagorico framework offre sono infiniti.
Fortunatamente il sito era già predisposto per la traduzione, quindi bastava preparare il file .po ed inserirvi le traduzioni. Lo strumento di cui mi sono servito, anche questa volta, è la potentissima console di CakePHP, che con il comando
/var/www/ilmiosito/app$ ./Console/cake i18n
ha cercato (da sola!!) tutte le stringhe traducibili in tutte le sottodirectory dell'applicazione "ilmiosito" (quelle scritte in modo simile a __('Traducimi', true), per intenderci) ed ha salvato il tutto, comodamente, nella directory ./app/Locale nella forma di un file con sintassi gettext, cioè qualcosa di simile a questo:
msgid "Translate me" msgstr "Traducimi"
... naturalmente, inserire la traduzione nella stringa msgstr rimane compito di chi scrive, non tutto è così automatizzato :)
Comodo, no?
Che noia aggiungere il file di configurazione in ogni file php...
... per fortuna che esiste l'.htaccess :)
Se si vuole includere un file (ad esempio un file di configurazione) in ogni singolo file php, può non essere necessario fare l'include tutte le volte; si può infatti fare in automatico con una semplice istruzione da mettere nell'.htaccess, così:
php_value auto_prepend_file "/percorso/del/file/config.php"
Allo stesso modo, se si vuole fare la stessa cosa ma al fondo dei propri file, si può utilizzare un'altra istruzione:
php_value auto_append_file "/percorso/del/file/stats.php"
Comodo, vero? :)
Come ti faccio un backup automatico dei database e lo salvo su dropbox
In questo fine settimana mi sono posto un problema non da poco per un webcoso freelance come me: e se il pc si rompe?
Faccio (quasi) abitualmente il backup dei dati che mi servono, ma il salvataggio dei database è sempre una rottura di scatole e lo faccio... solo quando mi ricordo di farlo. Questo non va bene perchè è un'operazione tediosa e troppo spesso finivo per trascurarla, così dopo aver scritto un piccolo script in bash per un altro motivo, ho deciso di sfruttare la comodità di questo strumento insieme alla figosità di Dropbox per avere un comando che faccia il lavoro sporco per me, lo faccia in automatico e lo faccia in modo sicuro, salvandolo anche online.
In sostanza, quello che fa questo script è effettuare il dump di tutti i database presenti sul mio mysql, eccetto le tabelle "sue", come information_schema, phpmyadmin e mysql, comprimerle tramite bzip2, controllare (basandosi sulla dimensione del file compresso) se ci sono stati dei cambiamenti dall'ultimo salvataggio ed eventualmente salvare il nuovo backup nella mia cartella su dropbox... poca spesa, tanta resa!
Ecco il codice:
#!/bin/bash ################################## # Mysql backup automatizzato con salvataggio dove ti pare (io uso dropbox). # Di Emanuele "ToX" Toscano - http://emanuele.itoscano.com/vedi/95 # Requisiti: linux o qualche adattamento per farlo funzionare su windows, non ho idea di come si faccia per mac # Consigliabile usare dropbox per salvare il file online da qualche parte, ma se non vuoi buon per te # Utilizzo: Mettilo nella directory in cui vuoi salvare il backup e lancialo. Al resto penserà lui da solo # Configurazione: la riga numero 20, quella con scritto mysql --user=root è l'unica che forse dovrai toccare per adattarlo alle tue necessità... se hai dubbi google è un portento ################################## if [ -d "$1" ]; then PERCORSO="$1" else PERCORSO=./mysql/ fi dbs="$(mysql -u root -Bse 'show databases')" for db in $dbs do if [ $db != "information_schema" ] && [ $db != "mysql" ] && [ $db != "phpmyadmin" ] && [ $db != "performance_schema" ] && [ $db != "test" ]; then # ATTENZIONE: aggiusta i dati della connessione mysqldump --user=root $db | bzip2 -c > /tmp/$db.sql.bz2 mv /tmp/$db.sql.bz2 $PERCORSO fi done
Comodo vero? Se qualcuno avesse consigli su come migliorarlo, naturalmente, i commenti sono li per questo... se qualcuno decidesse di riutilizzarlo in qualche modo faccia pure, ti pregherei solamente di lasciare il mio contatto in cima allo script (ma non verrò a tirarti le coperte la notte se non vorrete farlo, sta a te essere corretto :)
Un semplicissimo antispam con jQuery
Recentemente mi è capitato di dover implementare un semplice antispam su un mio sito, che riceveva quantità enormi di post spazzatura. Non volevo appesantire il tutto e non volevo usare script presi chissàddove, così, ricordando che la maggior parte dei bot non sa interpretare javascript, ho deciso di usare questo linguaggio come difesa; tantopiù che gli utenti senza javascript abilitato sono meno dell'1%, percentuale del tutto trascurabile (anzi, magari quell'1% è composto proprio dal bot :))
Per farla breve, ecco la ricetta del mio script:
Prima di tutto modifico l'action del mio form, da (per esempio) post/add a post/antispam_add
<form action="/post/antispam_add" id="idDelMioForm" method="post">
Aggiungo un pizzico di jquery:
$(document).ready(function(){
$('.submit input').click(function() {
action = $('#idDelMioForm').attr('action');
newaction = action.replace('antispam_', '')
$('#idDelMioForm').attr('action', newaction);
return true;
});
})
Scritto... e filtrato!
Semplice, no? :) In questo modo non c'è bisogno di utilizzare orribili captcha, che sono l'antitesi dell'usabilità, l'utente non si accorge di nulla ed otteniamo un buon risultato... sperando che i bot continuino a non interpretare codice javascript :)
Importare il dump di un database enorme in mysql
Mi è appena capitato di dover caricare il dump di un database di grosse dimensioni (oltre il centinaio di MB) su MySQL. Il tool di importazione di PhpMyAdmin supporta fino a 8MB e tool come bigdump non mi sono serviti a nulla...
Ma per fortuna che c'è la shell e che sono su linux!
Questo è il comando che mi ha salvato:
mysql -u utenteDiMySQL -p nomedeldatabase < dump.sql
Integrazione di YoxView con CakePHP
Quando dico niente di più semplice, credimi, intendo davvero niente di più semplice.
Vuoi implementare una lightbox basata su jquery, che sia veloce, funzionale, semplicissima da installare e che permetta di avere uno slideshow? Beh YoxView è tutto questo e molto altro.
L'installazione è banale: basta scaricare il pacchetto e scompattarlo in ./app/webroot/js, nella directory yoxview.
Poi devi creare un element chiamato yoxview.ctp e mettici dentro questa roba:
<?php
echo $this->Html->css('../js/yoxview/yoxview');
echo $this->Html->script('yoxview/jquery.yoxview-2.15.min');
echo $this->Html->script('yoxview/yoxview-init');
$initJs = "
$(document).ready(function(){
$('#content').yoxview({ //sostituisci #content con l'id di ciò che contiene le immagini
lang: 'it'
});
});
";
echo $this->Html->scriptBlock($initJs);
?>
Beh... sei libero di non crederci, ma l'integrazione è già fatta. Semplice vero?
Se vuoi vedere come funziona, dai un'occhiata in qualche pagina nella galleria o in slideshow...
Sottolineare parte di un testo con jQuery, senza plugins
Poco prima di scrivere questo post avevo una necessità: sottolineare alcune parole all'interno di un testo in base a ciò che avevo cercato tramite l'apposita funzione di ricerca.
Ho trovato diversi plugin per farlo, alcuni più pesanti, altri più leggeri... ma a me bastava una cosa semplice, magari senza dover caricare altri plugin!
Beh, cercando qua e la sono riuscito ad ottenere questo:
$.extend($.expr[":"], {
"containsNC": function(elem, i, match, array) {
return (elem.textContent || elem.innerText || "").toLowerCase().indexOf((match[3] || "").toLowerCase()) >= 0;
}
});
questo codice estende la funzione :contains di jQuery rendendola case insensitive (la funzione diventerà :containsNC)
$("p:containsNC('"+search+"')").addClass("highlight");
e quest'altro ricerca la parola e applica la classe "highlight" al paragrafo che contiene la parola. Naturalmente questo è ciò che serviva a me, ma dovrebbe essere semplice sottolineare solo la parola.
Far funzionare la proprietà css "display: inline-block" su internet explorer
Mi piacciono i misteri, soprattutto se servono a risolvere problemi complicati (o frustranti) in modo semplice e veloce.
In questi giorni stavo litigando con un layout scritto per un cliente, con delle icone posizionate una a fianco all'altra tramite una favolosa proprietà css: display: inline-block;
Ho testato tutto sugli ultimi browser e funziona perfettamente, mi permette di evitare gli amati/odiati float e il mio umore ne giova particolarmente.
I problemi sono inaspettatamente ( -_- ) giunti quando ho testato il tutto con internet explorer 6 e 7: semplicemente, non conoscono quella proprietà e la ignorano. Gli elementi se ne stavano tutti tristi uno sotto l'altro, e il mio umore era sotto di loro a reggerne il peso.
Insomma per farla breve, vagando su internet ho scoperto che con un piccolissimo ritocco ai miei css potevo far funzionare tutto, con un semplice (ed usuale, purtroppo) commento condizionale posizionato al fondo di tutti gli altri css:
<!--[if lt IE 8]>
<style type='text/css'>
* html #menu li { display:inline; } /* hack per IE 6 */
* + html #menu li { display:inline; } /* hack per IE 7 */
</style>
<![endif]-->
Capito? Neanche io! Però funziona e tanto mi basta, in attesa che queste carrette del web facciano finalmente la fine che meritano.
Naturalmente, #menu li è quello che nel mio codice sfrutta la proprietà display: inline-block.
Inoltre, per chi ne avesse la necessità segnalo che è possibile far funzionare questa proprietà anche su firefox 2, tramite un semplice (e hackoso) display: -moz-inline-box;
Il mio umore è nuovamente alto.
Script per il backup di database e webroot
Da tempo ero alla ricerca di uno script semplice e funzionale per effettuare i backup dei propri siti internet in modo automatizzato, che non desse lavoro una volta installato (tipo "installa e dimentica"). Alla fine mi sono imbattuto in questo vecchio post e nel bellissimo script che ancora adesso potete ammirare su quelle pagine.
Naturalmente dovevo modificarlo per le mie necessità, cioè renderlo agnostico riguardo alla directory in cui è installato (basta creare una directory qualunque, buttarci dentro i due file qua sotto e al resto pensa lui) ed effettuare il dump dei database...
Ma bando alle ciance:
#!/bin/bash CURPATH=$( cd $( dirname $0 ) ; pwd ) DIR_BKP="$CURPATH" # ========== CONFIGURATION ============ # file con i pattern da escludere dal backup EXCLUDES="$CURPATH/excludes" # nr di giorni da consevare NDAY=14 # prefisso della directory del backup PRE="backup_dati" # directory da backuppare TARGET="$CURPATH/../" # configurazione dati di accesso al database DBUSERNAME="username" DBPASSWORD="password" DBHOST="host.com" # ==================================== echo "=> Fase 0 ($(date '+%d-%m-%Y %H:%M')): Backup database" mysqldump --opt --user="$DBUSERNAME" --password="$DBPASSWORD" --host="$DBHOST" --all-database | gzip -v > "$DIR_BKP/database.tar.gz" # ==================================== echo "=> Fase 1 ($(date '+%d-%m-%Y %H:%M')): Cambio \ permessi e rimozione del backup piu' vecchio <=" # cambio permessi chmod -R 700 "$DIR_BKP/$PRE."* # Viene eseguita solo alla prima esecuzione if [ -e "$DIR_BKP/$PRE.0" ]; then echo "*" else echo "Prima esecuzione !!!" mkdir "$DIR_BKP/$PRE.0" fi; # rimozione del backup più vecchio if [ -d "$DIR_BKP/$PRE.$NDAY" ] ; then echo " rm -rf $DIR_BKP/$PRE.$NDAY" rm -rf "$DIR_BKP/$PRE.$NDAY" fi # ==================================== echo "=> Fase 2 ($(date '+%d-%m-%Y %H:%M')): Shifto \ di una unita' i backup esistenti <=" while [ $NDAY -gt 1 ]; do NDAY2=$(($NDAY-1)) if [ -d "$DIR_BKP/$PRE.$NDAY2" ] ; then echo " mv $PRE.$NDAY2 $PRE.$NDAY" mv "$DIR_BKP/$PRE.$NDAY2 $DIR_BKP/$PRE.$NDAY" fi; NDAY=$NDAY2; done # ==================================== echo "=> Fase 3 ($(date '+%d-%m-%Y %H:%M')): Creo \ hard link del backup piu' recente <=" if [ -d "$DIR_BKP/$PRE.0" ] ; then echo "cp -al $PRE.0 $PRE.1" cp -al "$DIR_BKP/$PRE.0 $DIR_BKP/$PRE.1" fi; # ==================================== echo "=> Fase 4 ($(date '+%d-%m-%Y %H:%M')): Eseguo \ il backup <=" # Verifica se c'è il file per le esclusioni if [ -r $EXCLUDES ] ; then EXCL="--delete-excluded --exclude-from=$EXCLUDES" else EXCL="" fi; #Comando di backup rsync -av --delete $EXCL $TARGET "$DIR_BKP/$PRE.0" #Sposto il backup del database mv "$DIR_BKP/database.tar.gz" "$DIR_BKP/$PRE.0/database.tar.gz" echo "=> Fase 5 ($(date '+%d-%m-%Y %H:%M')): Cambio i permesi in sola lettura <=" chmod -R 500 "$DIR_BKP/$PRE."* # ==================================== echo "=> FINE ($(date '+%d-%m-%Y %H:%M')) <="
ed impostare nel file "excludes" i files e le directory che si vogliono escludere dal backup:
- backups/ - logs/ - Maildir/ - tmp/ - cms.tar.bz2 - .links/ - .ssh
Fatto! Ora basterà lanciare da shell (o da crontab) lo script in questo modo:
sh backups/bk_daily.sh e al resto penserà lui da solo...