tags search: segnalazioni
LogHappens - come tenere d'occhio i log files, senza impazzire
Qualche tempo fa ho scoperto un tool dal nome divertente e con uno scopo utilissimo: poter tenere d'occhio log files, a piacimento, senza diventare matti interpretando file di testo da centinaia di righe, solitamente formattati in modo non troppo chiaro.
Tutto molto bello, peccato che creare dei nuovi parser è un delirio di regex, regole e requisiti non proprio chiarissimi... così ho iniziato a fare un mio parser.

LogHappened
Così è nato LogHappens. La grafica è minimale e molto semplice: un menu laterale in cui scegliere il log che si vuole visualizzare, un contatore per avere sempre un'idea di quante entries sono presenti per ogni log file... ed i log. Suddivisi come preferisci, anche se probabilmente farlo per data e ora è il modo più semplice. Quando succede qualcosa di nuovo, per esempio viene rilevato una nuova entry in uno dei file, LogHappens mostra un popup del browser (mostrato quindi dal sistema operativo, anche quando l'app non è in primo piano).
Sì, ma come funziona?
Il funzionamento, come dicevo, doveva essere molto semplice: In una cartella `logics` sono presenti tanti files quanti sono i log che vuoi tenere sotto controllo. Nella cartella `logics_templates` sono presenti invece, come puoi immaginare, alcuni esempi di file logics. Uno di questi serve per interpretare i log files di apache, e contiene questo codice:
<?php
$menu = [
'icon' => 'build',
'color' => 'red',
'title' => 'Apache error.log',
'file' => '/var/log/apache2/error.log'
];
$content = file($menu['file']);
$log = [];
foreach ($content as $line) {
// Grab the log's time and group logs by time
$time = substr($line, 1, 19);
$time = date("l d-m-Y - H:i:s", strtotime($time));
// Remove date-time and other useless informations from the log details
$line = substr($line, 34);
$line = preg_replace('[\[:error.*\]]', '', $line);
$line = preg_replace('[\[pid .*\]]', '', $line);
$line = str_replace('PHP', '', $line);
$line = trim($line);
// Highlight the type of errors, using a badge
$line = preg_replace("/^Notice: /", "Notice: ", $line);
$line = preg_replace("/^Warning: /", "Warning: ", $line);
$line = preg_replace("/^Fatal error: /", "Fatal error: ", $line);
$line = preg_replace("/^Parse error: /", "Parse error: ", $line);
$line = preg_replace("/^Error: /", "Error: ", $line);
// Save the log entry
$log[$time][] = $line;
}
// Reverse the logs, so that we can see last errors first
$logs = array_reverse($log);
Piuttosto semplice, non è vero? Modificando un po' questo file, è possibile creare un parser per virtualmente qualunque tipo di log file.
Sbloccare ed installare l'ultima MIUI in italiano su Xiaomi Redmi 4 PRO (forse vale anche per altri modelli)
NOTE:
Questa guida nasce dall’esperienza e da altre guide trovate in rete, serve per sbloccare telefoni XIAOMI con versioni farlocche di MIUI, come la 8.0.4.0 LXKCNMA che avevo io, che non sono aggiornabili e sono spesso malfunzionanti (non mi stupirei se contenessero dei malware, ma non ne ho idea). Se tu avessi già una versione ufficiale di MIUI installata sul telefono, puoi seguire la guida partendo dalla sezione "sblocchiamo il telefono".
Questa procedura è quella che ho seguito io, passo dopo passo, per sbloccare il mio Redmi 4 PRO. Ha funzionato senza problemi e non vedo perché non dovrebbe farlo anche con te, ma non mi assumo responsabilità di alcun tipo nel caso qualcosa non andasse per il verso giusto ![]() .
.
PREPARAZIONE:
-
Metti in carica il telefono ed attendi che arrivi al 100%. Aspettare un'ora in più e partire con il telefono carico al 100% è molto meglio rispetto al rischio di trovarsi un fermacarte perché il telefono si è scaricato totalmente durante uno dei passaggi
-
Nel frattempo, scarica la rom fastboot in versione developer (il formato del file deve essere .tgz e non .zip). Scompatta il file da qualche parte, facendo attenzione che nel percorso non ci siano spazi (es: “redmi” va bene, “redmi rom fastboot” no): http://en.miui.com/a-234.html
-
Scarica Mi Flash (beta): http://c.mi.com/in/thread-2434-1-1.html
-
Scarica i driver PDAnet, ricordandosi di sovrascrivere eventuali driver che secondo l’installer sono già presenti: http://pdanet.co/bin/PdaNetA4197.exe)
-
Installa Mi Unlock tool: http://en.miui.com/unlock/
-
Scarica minimal Adb/Fastboot: https://www.androidfilehost.com/?fid=457095661767103465
-
Scarica una recovery TRWP: https://www.androidfilehost.com/?fid=457095661767117508
-
Scarica l’ultima versione della miui da xiaomi.eu oppure miui.it (guida alla scelta)
-
OPZIONALE: Scarica SuperSU, pacchetto “Recovery Flashable.zip” se vuoi avere i permessi di root: http://www.supersu.com/download#zip
PROCEDURA PER INSTALLARE UNA ROM UFFICIALE:
-
Nelle impostazioni del telefono / informazioni, clicca diverse volte sulla versione della miui finché non risponde che sei un developer.
-
Cerca developer options in Additional Settings, abilita USB debugging e OEM unlocking.
-
Collega il telefono al PC.
-
Installa i drivers PDAnet, consentendo tutto ciò che viene richiesto.
-
Apri una console nella directory in cui è salvato adb/fastboot, poi digita “adb devices”. Se tutto va bene, questo comando dovrebbe mostrare un codice.
-
Digita “adb reboot edl”.
-
Apri Mi Flash, seleziona la cartella relativa al file .tgz che hai scompattato precedentemente, e clicca il bottone “refresh”.
-
La lista dovrebe mostrare il tuo telefono e dirti che è collegato ad una porta COMx.
-
Clicca su Flash, e aspetta che finisca il tutto. Se non dovesse funzionare prova con un’altra porta usb o prova a ripetere le ultime operazioni, da “adb reboot edl”.
-
-
Quando il flash è terminato, tieni premuto il tasto di accensione ed il telefono si accenderà. Ci vorranno diversi minuti quindi mettiti comodo.
-
Connetti la rete wifi, ma salta pure gli altri passaggi (incluso il MI Account che per ora non serve).
-
Come prima, attiva la modalità developer, abilita USB debugging e OEM unlocking. Sotto la voce OEM unlocking è presente un’opzione per collegare il MI Account. Fallo da qua ed ignora eventuali errori (a meno che non sia la password errata :)).
-
Copia il file .zip della miui nella cartella principale della memoria del telefono.
-
OPZIONALE: Copia anche il file di SuperSU nella stessa cartella.
SBLOCCHIAMO IL TELEFONO
-
Spegni il telefono e riavvialo in modalità fastboot (VOL- e tasto di accensione)
-
Sul pc, apri Mi Unlock Tool, inserisci le tue credenziali e segui i passaggi per sbloccare il telefono. Nel caso in cui ti fosse capitato seguendo altre guide, ora non dovrebbe più inchiodarsi al 50%.
INSTALLIAMO LA RECOVERY TWRP
-
Sul pc, torna sul prompt dei comandi nella cartella di adb/fastboot, e digita “adb devices”. Dai il consenso per eventuali popup che dovessero presentarsi.
-
Riavvia il telefono in modalità fastboot (VOL- e tasto di accensione)
-
Sul pc, dal prompt dei comandi digita “fastboot flash recovery recovery.img”. Questa operazione dovrebbe richiedere pochi secondi. Digita poi “fastboot boot recovery.img”
-
Il telefono si riavvierà con la nuova recovery TWRP. In cinese.
-
Se non conosci il cinese, limitati a flaggare la checkbox e fare lo slide sullo slider, poi clicca sul penultimo elemento in basso a destra. Nel menu in alto dovrebbe comparire un globo, cliccando quello puoi cambiare la lingua con quella che vuoi (consiglierei l’inglese, visto che le prossime istruzioni saranno in inglese)
INSTALLIAMO LA NOSTRA NUOVA ROM PREFERITA
-
Torna al menu principale di TWRP e clicca su “Wipe”. Conferma l’operazione con uno slide sullo slider.
-
Torna al menu principale e clicca su “Install”. Seleziona la rom che hai scaricato prima e seleziona “Flash”.
-
OPZIONALE: sempre dal menu Install, seleziona il pacchetto du SuperSU per avere il telefono con i permessi di root
-
Fai un wipe cache/dalvik
-
spegni il telefono tenendo premuto il tasto di accensione per parecchi secondi
-
Preparati ad aspettare circa 10 minuti per il primo avvio
FINE!
Linux ed il trackpad malfunzionante su Asus X556UA
Qualche giorno fa ho installato Ubuntu 16.10 su un portatile Asus X556UA. Tutto molto bello, molto stiloso, molto veloce (anche perché il portatile ha subìto l'upgrade a 12GB di ram e la sostituzione dell'hard disk con un SSD, facendolo diventare praticamente una scheggia). Il problema è che su alcuni portatili (tipo questo) il trackpad funziona in modo quantomeno discutibile: il puntatore schizza ovunque, lo scrolling non funziona e premere uno dei due tasti del trackpad significa spostare involontariamente il puntatore. Era quasi inutilizzabile.
Dopo un po' di ricerca mi sono imbattuto finalmente in un post in cui qualcuno, stufo della situazione e del fatto che Asus non intende rilasciare alcun driver per linux, si è scritto da solo un driver per far funzionare correttamente il trackpad.
Eccolo: https://github.com/vlasenko/hid-asus-dkms
I comandi per l'installazione sono scritti nella pagina, ma si tratta di un paio di comandi:
git clone https://github.com/vlasenko/hid-asus-dkms.git
cd hid-asus-dkms
sudo ./dkms-add.sh
Et voilà. Le modifiche sono immediate ed anche riavviando il portatile non dovrebbe più esserci alcun problema.
Finalmente!
Aruba e iThemes Security per WordPress: MAI abilitare "Disable Directory Browsing"
Se c'è una cosa in cui l'hosting di Aruba non fallisce mai, è sicuramente il creare inutili complicazioni: Non perde occasione per farlo.
Nella fattispecie, nel caso in cui tu stia utilizzando Wordpress ed il plugin iThemes Security per limitare i danni di questo fin troppo popolare CMS, potrebbe esserti già capitato che ad un certo punto, smanettando nelle opzioni del plugin di sicurezza, il sito inizi a rispondere con un laconico "errore 500". Risolvere è abbastanza semplice e se non si trattasse di Aruba lo sarebbe ancora di più, se non fosse per il ridicolo filtro sugli indirizzi ip di Aruba, che obbliga a cercare di districarsi nelle innumerevoli finestre aperte dal ridicolo pannello di controllo, che sembra arrivare dal passato senza aggiornamento alcuno.

Ad ogni modo, l'obiettivo è modificare il file `.htaccess`, presente nella directory principale del sito, ed eliminare queste due righe:
# Disable Directory Browsing - Security > Settings > System Tweaks > Directory Browsing Options -Indexes
Una volta effettuata questa modifica, è sufficiente salvare il file .htaccess ed il sito dovrebbe tornare ad essere visibile.
Per evitare il problema in futuro, è necessario tenere sempre a mente che questa opzione, su aruba, è da tenere necessariamente disattivata:

Disattivare l'autocomplete su chrome (ed altri browser)
Disattivare l'autocomplete per username e password dovrebbe essere una questione semplice, normalmente si tratta solamente di un
autocomplete='off'
da implementare a livello di singolo campo e/o di form. Purtroppo chrome ha deciso di fare a modo suo, e quell'attributo non è sufficiente. L'autocomplete lo vuole usare a tutti i costi, e se trova un campo di tipo password, lui presume che quello precedente sia lo username.
Disattivarlo è semplice, ma è un workaround degno di un Internet Explorer qualunque. Per raggiungere questo obiettivo, è sufficiente mettere -prima dei veri campi username e password- due campi nascosti e fasulli... chrome li vede, pensa di dover usare l'autocomplete lì e si lascia fregare.
Per farla breve, appena dopo l'apertura del form metti qualcosa del genere:
<!-- campi fasulli nascosti, per fregare chrome con l'autocomplete --> <input style="display:none" type="text" name="fakeusernameremembered"/> <input style="display:none" type="password" name="fakepasswordremembered"/>
Et voilà.
Ridicolo, no?
Alcuni siti si vedono male su chrome 44
Da quando Google Chrome 44 è stato rilasciato sono fioccati problemi di compatibilità con alcuni siti che non si vedono più correttamente, sembrano essersi persi dei pezzi o in generale si comportano in modo strano.
Beh, è un bug di questa versione di Chrome, che dovrebbe venire aggiornata a breve (il 27 luglio). Ad esserne affetti sono potenzialmente un po' tutti i siti. Personalmente ho riscontrato un problema su un sito PHP "fatto a mano" ed uno in Wordpress.
Nel frattempo, è possibile risolvere il problema "eliminando" due variabili di sessione che "confondono" questa versione di Chrome:
# Fix for CHROME 44 https bug unset($_SERVER['HTTP_HTTPS']); unset($_SERVER['HTTPS']);
Tutto lì. A saperlo prima, mi sarei evitato qualche ora di debug... :)
Prima ti obbligo e poi ti spiego come farlo: Chiarimenti sulla cookie law
Visto che continua ad esserci moltissima confusione sulla cookie law, il Garante della Privacy ha pensato che potesse essere utile spiegare come mettersi in regola con la legge, che nel frattempo era già entrata in vigore.
Lo ha fatto con una semplice immagine (bisogna ammettere che è -abbastanza- ben fatta) che chiarisce probabilmente molti più dubbi di quanto avrebbero fatto intere paginate di spiegazioni in burocratese, quindi... ecco a voi.

Ora, probabilmente non è ancora del tutto chiaro... cosa significa "ridurre il potere identificativo", per esempio? Io uso il servizio X, sono in regola? A questo viene in soccorso un altro sito, quello di SqueezeMind, che ha preparato un paio di altre belle grafiche ed una spiegazione finalmente comprensibile dagli addetti ai lavori.
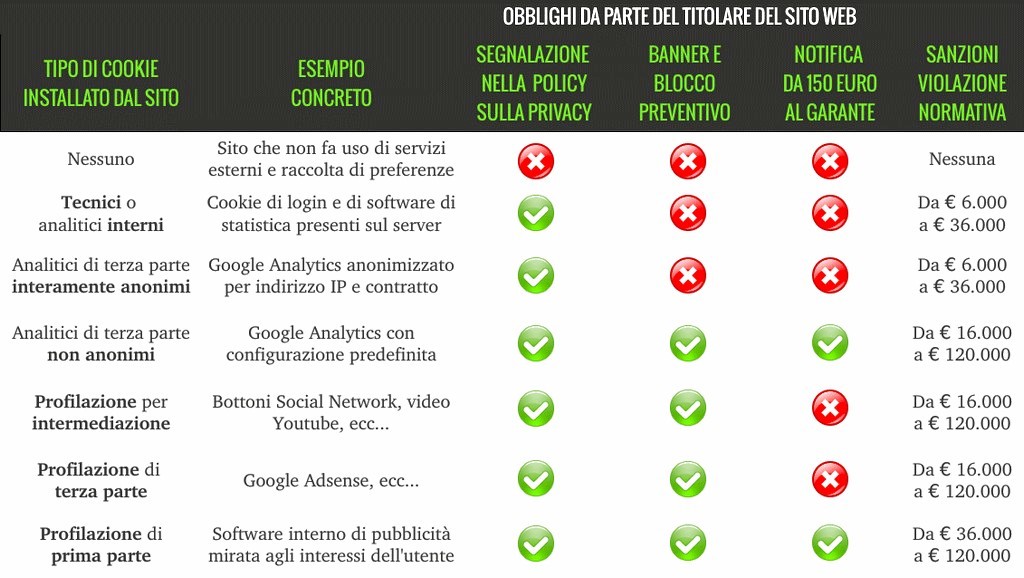

Non perderti la spiegazione, la puoi trovare sul loro sito.
Aruba e "No input file specified."
 Lavoro nel campo dello sviluppo web da quasi un decennio ormai, eppure alcuni hosting continuano a stupirmi ogni volta che ho a che fare con loro. Uno di questi è aruba, che con il suo pannello di controllo che sembra arrivare dagli anni 90 continua a mettermi in difficoltà fin dalla prima volta che l'ho conosciuto.
Lavoro nel campo dello sviluppo web da quasi un decennio ormai, eppure alcuni hosting continuano a stupirmi ogni volta che ho a che fare con loro. Uno di questi è aruba, che con il suo pannello di controllo che sembra arrivare dagli anni 90 continua a mettermi in difficoltà fin dalla prima volta che l'ho conosciuto.
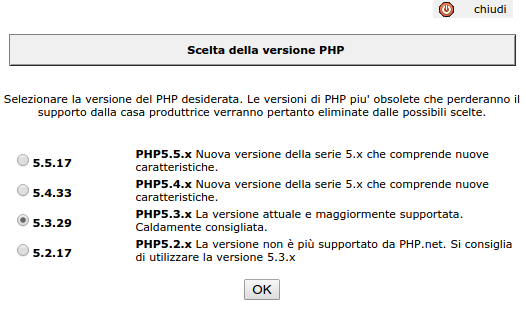
Questa volta si è trattato del sito di un cliente, online da alcuni anni, che in questi giorni ha deciso di spostare il tutto su aruba. Di solito è sufficiente trasferire file e database, modificare un file di configurazione, svuotare la cache ed il gioco è fatto ma stavolta mi sono imbattuto in un errore strano: L'home page funzionava perfettamente ma tutte le altre pagine mostravano un triste messaggio "No input file specified.", nero su bianco. Impenetrabile come la nebbia della bassa padana.
Dopo interminabili ricerche su internet, una (inutile) ri-esecuzione della copia di file e database, qualche momento di stupore nello scoprire che è "caldamente consigliata" la versione 5.3.29 di PHP ("PHP5.3.x La versione attuale e maggiormente supportata. Caldamente consigliata." il cui supporto è terminato mesi fa) e che la versione 5.4 (uscita nel 2012) è considerata la "Nuova versione della serie 5.x che comprende nuove caratteristiche", eccetera... finalmente ho capito il problema. Il file php.ini di default su aruba contiene un'istruzione cgi.fix_pathinfo = 0 che su alcuni siti (per esempio joomla, o nelle versioni vecchie di CakePHP) può dare problemi.
Per risolvere questa scocciatura è sufficiente andare nel "magnifico" pannello di controllo, cercare (navigando fra le mille finestre che aruba gentilmente ci propone) la voce Personalizzazione del file PHP.INI ed all'interno di quella nuova finestra selezionare cgi.fix_pathinfo, che imposta il relativo valore a 1.
Fatto questo, dovrebbe tornare tutto a funzionare. O almeno si spera...
Guida facile per il root del Nexus 5
Ho da poco acquistato questo (enorme) telefono e dopo soli due giorni di utilizzo non riesco a resistere alla tentazione di installargli qualche sistema operativo diverso da android stock: penso in particolare a ubuntu touch (perlomeno per provarlo, anche se non credo sarà il mio sistema predefinito), ma anche a cyanogenmod (da usare normalmente).
Su internet ho trovato decine di guide ma tutte richiedono l'installazione di drivers, applicazioni, cose... finché non mi sono imbattuto in un piccolo tool che rende davvero semplice il tutto: è sufficiente lanciare un comando per ritrovarsi il telefono resettato (questo avviene con qualunque sistema, purtroppo) e rootato.
Ecco i passaggi:
- Per prima cosa bisogna scaricare ed estrarre questo file sul proprio computer.
- Poi bisogna spegnere il telefono e riaccenderlo tenendo premuto il tasto volume +, volume - ed il tasto di accensione. Il nexus si riavvierà in modalità "sala operatoria", con tanto di logo android con il "cofano" aperto.
- Infine si collega il telefono al computer utilizzando un normale cavetto usb.
A questo punto è sufficiente lanciare root-windows.bat, root-linux.sh o root-mac.sh a seconda del sistema operativo che stiamo utilizzando. La procedura guidata farà comparire una richiesta sul telefono per sapere se vogliamo sbloccare il boot loader oppure no (e noi lo vogliamo, naturalmente), e dopo un paio di riavvii avremo il nostro nexus sbloccato.
Facile, no?
SublimeLinter: un comodo quasi-debugger per Sublime Text
Ok, debugger non è il termine corretto. In realtà questo pacchetto si occupa di "linting", cioè controlla il codice per potenziali errori e li evidenzia in modo tale da renderli chiaramente visibili allo sbadato programmatore.
Per esempio, niente più ; mancanti al termine di un'istruzione PHP, sublimeLinter evidenzierebbe subito la riga di rosso. Così come niente più parentesi non chiuse in CSS, niente più dichiarazioni duplicate, niente più... dimenticanze o sviste di questo tipo. Con grande risparmio di tempo e di energia nel cercare di debuggare una funzione semplicissima che si ostina a non funzionare... diavolo di una virgola mancante :)
L'installazione è semplicissima, così come ogni altro plugin per Sublime Text: si apre il package installer, si seleziona "sublime linter" e... si installa :)
Funziona tutto fin da subito , senza troppi sbattimenti e volendo c'è anche un piccolo menu per configurare più facilmente il comportamento del plugin. L'unica altra modifica che ho fatto è stata disabilitare gli avvisi durante il linting dei file CSS, per fargli ignorare l'uso dell'istruzione !important e degli ID .
Per farlo, è stato sufficiente aprire il SublimeLinter settings - user, andare alla riga degli ignore per il csslint e sostituirla con :
"ignore": "important,ids",
L'unica cosa che manca a questo pacchetto è il linting per i Javascript, che è da abilitare a parte. Per farlo è sufficiente installare il pacchetto sublimelinter-jshint, installare jshint... e godersi anche quest'altra sciccheria.
user@linuxbox:~$ npm install -g jshint
Facile, no? :)
Adminer: un'ottima alternativa al pachidermico phpMyAdmin
Ho recentemente -e casualmente- scovato un'ottima alternativa a phpMyAdmin, che è da sempre il mio strumento prediletto per gestire i database MySQL ma di cui non sono mai stato veramente soddisfatto. Da quando ho iniziato ad usarlo l'ho sempre lento, incongruente e... poco usabile. L'alternativa si chiama Adminer e già dall'home page si può notare come il progetto sia decisamente ambizioso: le priorità sono:
- Sicurezza
- Usabilità
- Performances
- Features
- Dimensioni
... dimensioni? Già :) Al contrario dei quasi 15Mbyte che sono richiesti da un'installazione di phpMyAdmin, Adminer richiede solamente poche centinaia di Kilobyte (un po' più di 300), in un unico file php. Questo lo rende un ottimo strumento "usa e getta" per operazioni di manutenzione. Volendo è anche possibile modificare l'interfaccia grafica posizionando uno dei file CSS proposti sul sito stesso nella stessa directory di adminer.php.
Lo sto usando da un paio di settimane e... mi sa che ho trovato il mio nuovo database manager :)
Libro "Instant CakePHP Starter", di Mark Robert Henderson
Alcuni giorni fa ho ricevuto un contatto da parte di Packt Publishing, casa editrice specializzata in libri di informatica (dalla programmazione alla grafica, con tutto quello che ci sta in mezzo), in cui mi fornivano l'opportunità di recensire un libro su CakePHP, scritto da Mark Robert Henderson, chiamato "Instant CakePHP Starter".
Avevo già fatto qualcosa del genere in passato, così ho accettato di buon grado.

Quello che mi ha incuriosito fin da subito è quell'"INSTANT" che fa capolino sin dalla copertina, seguito da "Short | Fast | Focused". Tutte caratteristiche che ritengo fondamentali in un libro/manuale di programmazione: odio perdere giorni a leggere teoria, preferisco andare al sodo e poter provare direttamente, magari contemporaneamente, quello che sto studiando.
Cosa è
Questo libro fa esattamente quanto promesso dalla copertina: l'autore parte da un'esigenza pratica e, dopo una breve panoramica sul framework e sul pattern MVC, ci spiega come creare l'applicazione dall'inizio alla fine, spiegando i vari passaggi intermedi: l'installazione, la configurazione iniziale, l'utilizzo del tool da riga di comando "cake", fino alla pubblicazione online, sfruttando il servizio gratuito di AppFog. Nel giro di poche decine di pagine Mark ci mostra come, sfruttando automatismi e convenzioni, CakePHP sia in grado di generare un'applicazione funzionante, seppur grezza, scrivendo pochissime linee di codice.
Poco dopo la metà del libro, dopo aver creato la nostra applicazione, l'autore va avanti e ci illustra altre importanti funzionalità di Cake: routing, themes, behaviors, fixtures e tests.
Secondo me
Quello che mi è piaciuto maggiormente di questo libro è che nel giro di poche pagine (un'ottantina in tutto) offre una bella panoramica di quanto offre CakePHP e lo fa in modo piacevole e diretto, senza tralasciare gustosi particolari. È un libro adatto sia a chi sta iniziando a conoscere questo bellissimo framework sia a chi, come me, lo utilizza già da alcuni anni ma ha sempre qualcosa da imparare o da migliorare. E poi... costa meno di 10 euro, è decisamente abbordabile ;)
Effettuare il dump di una tabella MySQL da php
Recentemente mi è capitato di dover creare uno script PHP che effettuasse il dump di una tabella di un database MySQL e la salvasse in un file, magari con compressione gzip.
Su internet ci sono decine di risorse, qualcuna fatta a mano, qualcuna che sfrutta il (comodissimo) programma mysqldump, ma nessuno propriamente personalizzabile: a me serviva qualcosa che tirasse giù i dati, magari in una sola insert e non in duecentomila, ma che all'occorrenza mi permettesse anche di inserire le istruzioni di DROP TABLE e la seguente CREATE.
Così, sfruttando parte di script scritti da qualcun altro, me ne sono creato uno da me. Lo riporto qua, sperando che possa essere utile a qualcuno.
Clicca per vedere lo script!
Come avere il kernel aggiornato sulle distribuzioni debian compatibili
Avere un kernel sempre aggiornato, su distribuzioni compatibili con debian ed ubuntu, è molto semplice grazie ai pacchetti che si possono trovare qua:
http://kernel.ubuntu.com/~kernel-ppa/mainline/
E' necessario entrare nella directory del kernel desiderato e scaricare i pacchetti compatibili con la propria architettura (i386 per i processori 32bit o amd64 per quelli a 64bit). Una volta scaricati, sarà sufficiente metterli in un'unica cartella ed installarli con
dpkg -i *.deb
Il tutto è chiaramente molto semplice, anche troppo... un utente inesperto o alle prime armi dovrebbe evitare cose di questo tipo, perchè non è detto che vada tutto a buon fine e che non ci siano incompatibilità con altre librerie.
Se volessi invece testare un kernel in fase di sviluppo, esiste anche una directory "daily", con i kernel aggiornati giornalmente... In questo caso, aspettati qualche problema :)
Scrivere un semplice accordion con jQuery
Mi è recentemente capitato di dover utilizzare un accordion per un semplice menu, con poche voci, per cui non volevo utilizzare jquery-ui o plugin simili. In giro è pieno di articoli che spiegano come creare un accordion ma, vista la facilità con cui si può realizzare una cosa simile, volevo provare a cimentarmi io stesso e soprattutto volevo imparare a creare un plugin, cosa che non ho mai provato a fare.
Il risultato si può vedere su jsFiddle (un ottimo tool per esperimenti di questo tipo) a questo indirizzo: http://jsfiddle.net/WpAXA/.
Analizziamo quello che ho fatto. Tralascio la parte di Html e di Css, che sono davvero banali e mi concentro sul codice javascript:
(function($) {
$.fn.tinyAccordion = function(options) {
}
})(jQuery);
Questo è il wrapper che ci permette di creare il nostro plugin. Sfruttando questo, posso eseguire la funzione lanciandola in questo modo:
$('#accordion').tinyAccordion({
'bookmark': 'h3',
'content': 'ul'
});
Come hai visto, ho passato delle opzioni che sono 'bookmark' e 'content', rispettivamente per indicare quale elemento deve essere la parte cliccabile dell'accordion (i tag h3) e quali parti devono essere visualizzate o nascoste, a seconda di cosa clicco (i tag ul). Come fare per dire alla mia funzione "Hey! Ti ho passato delle opzioni, usa quelle!", e come fare se invece non le avessi specificate? Ci pensa questo pezzetto di codice:
// valori di default
var config = {
'bookmark': 'h3',
'content': 'div'
};
$this = this.selector;
if (options) $.extend(config, options);
In particolare, nella variabile config imposto i valori di default (quelli che verrebbero utilizzati nel caso in cui non li avessi specificati io), mentre l'ultima riga "unisce" gli array delle due variabili. Naturalmente quelle specificate a mano hanno la priorità sulle altre.
E la penultima riga? Quella mi serve per impostare in una variabile qual è il nome dell'elemento per cui deve essere eseguita questa funzione (#accordion, nel mio esempio).
bookmark = $($this + " " + config.bookmark); content = $($this + " " + config.content);
Come prima, anche qua ho creato delle variabili per sapere su quali elementi devo agire. In particolare, quando javascript eseguirà questo blocco le variabili avranno come valore rispettivamente $("#accordion h3") e $("#accordion ul").
var i = 1;
bookmark.each(function() {
$this = $(this);
$this.attr("data-accordion-switch", "el" + i);
$this.next(config.content).attr("data-accordion-list", "el" + i);
i++;
});
Gli ultimi preparativi prima del via. In questo blocco cerco tutti gli elementi che corrispondono alla variabile bookmark (te lo ricordo, è $("#accordion h3")), e per ognuno creo un attributo data. Lo stesso valore viene utilizzato per il rispettivo contenuto. Questo serve per creare una corrispondenza fra un bookmark e ciò che dovrà visualizzare o nascondere.
bookmark.on('click', function() {
$this = $(this);
var element = $(config.content + '[data-accordion-list="'+ $this.data('accordionSwitch') +'"]');
content.slideUp('fast');
if (element.is(":hidden")) {
element.slideDown('fast');
}
});
Ora viene il bello: il blocco precedente è quello che si occupa di aprire o chiudere i contenuti in base al bookmark che hai cliccato. Tutto li? Tutto li!
La prima riga crea una funzione che viene lanciata ogni volta che clicco su un bookmark. Subito dopo, avrai notato che inizializzo una variabile $this. Di nuovo? Non sono impazzito: questa variabile mi serve solo all'interno di questa funzione (ed esiste solamente li) ed ha uno scopo ben preciso che non è solo la comodità come nel caso precedente: Non tutti sanno, infatti, che ogni volta che utilizzi $(elemento) viene eseguita una funzione di jQuery che scorre il DOM per trovare il riferimento all'elemento corrispondente. Se invece metto il riferimento stesso in una variabile, risparmio questo lavoro al processore. Detto in linguaggio più umano: sfruttare questa tecnica è come creare un indice ad un libro, permettendo al lettore di trovare immediatamente quello che serve senza dover scorrere tutte le pagine. In realtà la differenza in termini di tempo è piccolissima perchè i computer odierni sono veloci, ma è una buona abitudine usare questa tecnica tutte le volte che si può.
Proseguiamo: alla terza riga creo una variabile che, una volta eseguita, avrà un valore simile a $("#accordion ul[data-accordion-list=el1]"). Questo è il selettore del blocco che corrisponde al bookmark che ho cliccato.
Successivamente, eseguo uno slideUp su tutti i contenuti e, se l'elemento selezionato era nascosto al momento deli click, lo faccio visualizzare, se invece era già visualizzato lascio che la funzione precedente lo faccia chiudere.
Ecco l'accordion!
Forse hai notato che prima di chiudere la funzione c'è un
return this;
Questo non è fondamentale nel nostro esempio, ma è un'altra di quelle cose che è buona norma inserire, quando possibile. Serve infatti a concatenare altre funzioni successivamente alla nostra. Per farti un esempio, parlo di concatenazioni tipo
$('#accordion').tinyAccordion().azione().altrazione().css(...)
Non è poi così complicato creare un plugin che implementi un accordion, vero?
Come ti faccio un backup automatico dei database e lo salvo su dropbox
In questo fine settimana mi sono posto un problema non da poco per un webcoso freelance come me: e se il pc si rompe?
Faccio (quasi) abitualmente il backup dei dati che mi servono, ma il salvataggio dei database è sempre una rottura di scatole e lo faccio... solo quando mi ricordo di farlo. Questo non va bene perchè è un'operazione tediosa e troppo spesso finivo per trascurarla, così dopo aver scritto un piccolo script in bash per un altro motivo, ho deciso di sfruttare la comodità di questo strumento insieme alla figosità di Dropbox per avere un comando che faccia il lavoro sporco per me, lo faccia in automatico e lo faccia in modo sicuro, salvandolo anche online.
In sostanza, quello che fa questo script è effettuare il dump di tutti i database presenti sul mio mysql, eccetto le tabelle "sue", come information_schema, phpmyadmin e mysql, comprimerle tramite bzip2, controllare (basandosi sulla dimensione del file compresso) se ci sono stati dei cambiamenti dall'ultimo salvataggio ed eventualmente salvare il nuovo backup nella mia cartella su dropbox... poca spesa, tanta resa!
Ecco il codice:
#!/bin/bash ################################## # Mysql backup automatizzato con salvataggio dove ti pare (io uso dropbox). # Di Emanuele "ToX" Toscano - http://emanuele.itoscano.com/vedi/95 # Requisiti: linux o qualche adattamento per farlo funzionare su windows, non ho idea di come si faccia per mac # Consigliabile usare dropbox per salvare il file online da qualche parte, ma se non vuoi buon per te # Utilizzo: Mettilo nella directory in cui vuoi salvare il backup e lancialo. Al resto penserà lui da solo # Configurazione: la riga numero 20, quella con scritto mysql --user=root è l'unica che forse dovrai toccare per adattarlo alle tue necessità... se hai dubbi google è un portento ################################## if [ -d "$1" ]; then PERCORSO="$1" else PERCORSO=./mysql/ fi dbs="$(mysql -u root -Bse 'show databases')" for db in $dbs do if [ $db != "information_schema" ] && [ $db != "mysql" ] && [ $db != "phpmyadmin" ] && [ $db != "performance_schema" ] && [ $db != "test" ]; then # ATTENZIONE: aggiusta i dati della connessione mysqldump --user=root $db | bzip2 -c > /tmp/$db.sql.bz2 mv /tmp/$db.sql.bz2 $PERCORSO fi done
Comodo vero? Se qualcuno avesse consigli su come migliorarlo, naturalmente, i commenti sono li per questo... se qualcuno decidesse di riutilizzarlo in qualche modo faccia pure, ti pregherei solamente di lasciare il mio contatto in cima allo script (ma non verrò a tirarti le coperte la notte se non vorrete farlo, sta a te essere corretto :)
[Recensione] CakePHP 1.3 Application Development Cookbook
Una doverosa premessa
Fin da quando sono entrato nel colorato e caramelloso mondo multiforme dell'informatica ho sempre prediletto blog e siti tematici; ho un brutto rapporto con manuali, libri e quant'altro riguardante la programmazione: ne ho acquistati alcuni insieme a riviste o per conto mio, ma immancabilmente la loro fine è quella di essere riposti in uno scaffale il giorno stesso o di restare sul tavolo in attesa di decidere cosa farne.
Qualche tempo fa sono stato contattato per recensire "CakePHP 1.3 Application Development Cookbook", di Mariano Iglesias. Conosco di fama Mariano Iglesias perchè diverse volte, cercando informazioni su come-fare-cosa su CakePHP mi sono imbattuto in alcuni suoi contributi, così, vista la mia stima nei suoi confronti, pur senza averci mai avuto a che fare direttamente, mi sono incuriosito e ho deciso di provare a farne una recensione.
Il libro
Il libro, che mi è arrivato in formato elettronico, è sostanzialmente un incrocio fra un manuale "pratico" ed un libro di ricette. Cookbook è un nome perfettamente azzeccato, e come tale è consigliabile leggerlo: se per esempio avessi bisogno di sapere cosa sono e come funzionano i Test, argomento su cui ho sempre avuto molte lacune e su cui non sono mai riuscito a trovare qualcosa di realmente utile a riguardo, mi basterebbe aprire il libro su quel capitolo per scoprire cosa sono, come funzionano e trovare degli esempi pratici su come usarli. Esempi che non sono mai banali (non è un libro per principianti: è infatti indicato per utenti medio-avanzati, categoria nella quale spero di potermi inserire).
Ogni capitolo si suddivide in un'introduzione, che spiega genericamente l'argomento trattato, e la parte tecnica, suddivisa a sua volta in almeno 3 sottocapitoli: getting ready (preparazione dell'ambiente di lavoro), how to do it (il codice vero e proprio, spesso con immagini e screenshot per rendere graficamente più chiaro il tutto) e how it works (che spiega ciò che succede nelle due parti precedenti). In alcuni capitoli è presente anche un there's more, che contiene curiosità o altre funzioni o funzionalità correlate.
Gli argomenti trattati
Il libro è composto da 11 capitoli per altrettanti argomenti in ambiti piuttosto vari e diversi fra loro; ecco di cosa tratta (cliccando sul link potete vedere come vengono sviscerati i singoli argomenti):
Preface
Chapter 1: Authentication
Chapter 2: Model Bindings
Chapter 3: Pushing the Search
Chapter 4: Validation and Behaviors
Chapter 5: Datasources
Chapter 6: Routing Magic
Chapter 7: Creating and Consuming Web Services
Chapter 8: Working with Shells
Chapter 9: Internationalizing Applications
Chapter 10: Testing
Chapter 11: Utility Classes and Tools
Index
Non male eh?
Personalmente ho trovato incredibilmente interessanti e utili i capitoli su "model bindings", "validazione" e "testing", che poi erano anche i punti su cui avevo più confusione in testa, ma anche il resto è ben scritto e molto chiaro. Mariano ha avuto l'ottima intuizione di scrivere un libro che richiede una discreta esperienza su CakePHP per essere letto e compreso a fondo, raggiungendo il suo scopo in modo chiaro e diretto.
Il verdetto finale
Sarebbe fuorviante dare un voto univoco al libro, in quanto può essere molto utile per chi ha una buona infarinatura generale su CakePHP e vuole migliorarsi, mentre per chi sta iniziando sarebbe probabilmente un libro troppo difficile da comprendere.
Mi piace moltissimo la struttura a "ricettario", mentre ho apprezzato meno la formattazione del codice. D'altra parte un libro non è un monitor, per cui un bellissimo pezzo di codice, che sul computer sarebbe perfettamente leggibile, su carta ha dei ritorni a capo che ne rendono difficoltosa la lettura. Avrei apprezzato anche se gli esempi di codice avessero avuto un po' di colore; il fatto che sia scritto tutto in nero non aiuta molto il "colpo d'occhio". Non so se sia tecnicamente fattibile, ma mi sarebbe piaciuto davvero moltissimo se insieme al libro ci fosse stato un insieme di file con i vari snippet di codice in formato testuale, da aprire con il proprio editor preferito...
Detto questo, rimane un libro perfettamente godibile pur con queste piccole pecche, che immagino siano un limite del formato stesso con cui viene fornito, cartaceo o ebook.
Dimenticavo... il libro è totalmente in inglese! Un inglese perfettamente chiaro e leggibile; non credo che possa creare problemi particolari a qualcuno, visto che nell'informatica l'inglese è un po' ovunque, ma è bene saperlo per evitare sorprese ![]() .
.
Gli strani colori delle immagini su Firefox4 con Ubuntu 11.04
Da quando ho aggiornato ad Ubuntu 11.04 firefox ha cominciato a fare cose strane, per esempio immagini come questa

Venivano visualizzate così:

Per qualche tempo ho provato ad utilizzare chromium, ma non riesco proprio ad abituarmici, e soprattutto a rinunciare ad alcune estensioni... poi ho scoperto questa discussione, che riportava a questa soluzione (in particolare Some images are displayed with weird colors).
Beh, ha funzionato :)
Html5: chi supporta cosa, con tanto di esempi
Mi sono imbattuto per caso in questo interessante sito...
Parecchio interessante e comodo per chi sta pensando, come me, di iniziare a lavorare seriamente in HTML5...
Anche Digg dice addio a Mysql
Dopo twitter, anche Digg ha deciso di migrare i propri dati da MySQL a Cassandra, un database non relazionale open source di seconda generazione, realizzato inizialmente da Facebook.
Il motivo principale della scelta, secondo quanto scritto sul blog di John Quinn è principalmente la difficoltà di gestire una infrastruttura ad alte prestazioni con enormi quantità di dati in veloce crescita come quella di un social network come Digg.
Cassandra offre una struttura più scalabile e più elastica, distribuita su più macchine e meno legata ad uno schema rigido di campi e tabelle.
Che siano le prime avvisaglie del declino per i database relazionali, almeno per le grosse applicazioni?
[Segnalazione] Domande e risposte su CakePHP
Girovagando per la rete mi sono imbattuto in questo simpaticissimo sito: All questions at CakePHP Questions.
È un luogo in cui, in modo molto semplice, chi ha bisogno di aiuto può fare la propria domanda, per poi attendere eventualmente la risposta dagli altri.
Molto utile!
Microsoft: "Abbandonate Internet Explorer 6!"
In seguito alla recente scoperta della vulnerabilità su Internet Explorer, Microsoft ha colto la palla al balzo per suggerire, tramite Technet, di aggiornare Explorer 6 ad una versione più recente. Pur restando dell'avviso che anche nelle versioni più recenti la situazione resta tragica, almeno per quanto riguarda il supporto agli standard web, devo riconoscere che Microsoft ha fatto un'ottima mossa, speriamo che gli utenti raccolgano il suggerimento e che explorer 6 sparisca finalmente dal mercato...
| Windows 2000 | Windows XP | Windows Vista | Windows 7 | |
| Internet Explorer 6 | Exploitable | Exploitable (current exploit effective for code execution) | N/A (Vista ships with IE7) |
N/A (Windows 7 ships with IE 8) |
| Internet Explorer 7 | N/A (IE 7 will not install on Windows 2000) |
Potentially exploitable (current exploit does not currently work due to memory layout differences in IE 7) | IE Protected Mode prevents current exploit from working. | N/A (Windows 7 ships with IE 8) |
| Internet Explorer 8 | N/A (IE 8 will not install on Windows 2000) |
DEP enabled by default on XP SP3 prevents exploit from working. | IE Protected Mode + DEP enabled by default prevent exploit from working. | IE Protected Mode + DEP enabled by default prevent exploit from working. |
Nota bene: Internet explorer 7 e 8 sono sicuri sono quando sono abilitate DEP e Protected mode, altrimenti la vulnerabilità è presente anche li!!
Per maggiori informazioni rimando al link del blog di Technet
Aggiornamento: Microsoft Italia ha pubblicato un video che cerca di rassicurare gli animi:
Siccome sono un malpensante aggiungo che NSS Lab, citata in questo video, quando ha fatto quella valutazione è stata probabilmente pagata da Microsoft, e che ha condotto il test in modo un po' strano, per esempio utilizzando versioni beta (opera) o obsolete (firefox) di alcuni software.
Comunque che per chi volesse controllare c'è il sito di Secunia, che permette di visionare la quantità ed il tipo di bachi conosciuti per ogni software, e la loro pericolosità:
Allarme dall'autorità federale per la sicurezza informatica tedesca: "Internet explorer non è sicuro"
Molte persone, un po' maliziosamente, l'hanno sempre sostenuto, ma stavolta l'allarme arriva nientemento che dal Bundesamt fuer Sicherheit in der Informationstechnik, BSI, ovvero l'Autorità Federale per la Sicurezza nella Tecnologia dell'Informazione, che ne sconsiglia l'uso in favore di browser alternativi, di cui fa anche i nomi: Firefox, Opera, Chrome o Safari.
La falla, presente nelle versioni 6, 7 e 8 del browser di casa Microsoft, e che interessa i sistemi operativi XP, Vista, 7, 2003 e 2008 server, permette di lanciare attacchi ed installare programmi pericolosi sul proprio computer e nella rete. La falla è stata confermata dalla stessa Microsoft, che ammette che l'unica versione al sicuro da questo baco è Explorer 5 su Windows 2000 (tecnologia vintage di 10 anni fa).
Sempre Microsoft ammette che l'attacco ai danni di Gmail partito dalla Cina qualche giorno fa potrebbe essere partito da questa vulnerabilità (fonte).
Non meno importante è l'accusa da parte mia di essere una gran rottura durante lo sviluppo di siti internet.
Il consiglio, da parte di tutti, è di cambiare browser, approfittando dello stato di necessità :).
Aggiornamento: Anche in Francia il Centre d'Expertise Gouvernemental de Réponse et de Traitement des Attaques informatiques consiglia l'uso di browser alternativi a fronte della vulnerabilità.
Aggiornamento 2: Ecco il bollettino Microsoft, con tanto di lista dei software affetti dal problema e quelli non affetti, più alcune precisazioni.
Il Millennium Bug arriva 10 anni dopo. Avrà usato trenitalia?
In ritardo di 10 anni, il famigerato Millennium Bug fa vedere i suoi effetti: alcuni telefonini, bancomat e antivirus danno segni di squilibrio apparentemente inspiegabili... ecco perchè:
Pensavate che il Millennium Bug, con la relativa angoscia planetaria per la gestione corretta del cambio di data fra il 1999 e il 2000 da parte dei computer, fosse solo un brutto ricordo o addirittura una bufala? E’ ancora fra noi. Dalla mezzanotte del 31 dicembre scorso, i telefonini con Windows Mobile 6.1 e 6.5 e con altri sistemi operativi ricevono talvolta SMS dal futuro, datati 2016. La causa è probabilmente un errore nel software che interpreta i codici usati per rappresentare l’anno negli SMS: secondo i commenti su Slashdot.org, la data negli SMS è in formato BCD mentre altri campi sono in formato esadecimale, per cui è possibile che alcuni software per cellulari (o nei gateway degli operatori) interpretino il codice dell’anno trattandolo come un esadecimale. In alternativa, si tratta di un astutissimo piano per evitare la fine del mondo nel 2012, prevista dal calendario Maya, passando direttamente al 2016. Su WMexperts c’è una prima possibile pezza non ufficiale (da usare a vostro rischio e pericolo). In Australia, intanto, alcuni sportelli bancari automatici stanno rifiutando le carte bancarie dei clienti da Capodanno, secondo quanto riferisce il Brisbane Times, perché i Bancomat pensano che l’anno corrente sia il 2016 e quindi a loro risulta che tutte le carte degli utenti sono scadute. Anche gli antivirus sono vulnerabili al Baco del Millennio e Dieci: la suite di sicurezza Symantec Endpoint Protection rifiuta tutti gli aggiornamenti successivi al 31 dicembre 2009 perché li considera scaduti. Il rattoppo temporaneo di Symantec consiste nel pubblicare gli aggiornamenti tenendo la data del 31 dicembre 2009 e incrementando il numero di versione. Fonte: http://attivissimo.blogspot.com