Blog
Pre-push GIT Hook - Aggiornare un sito remoto ed il database tramite SSH con un git push
In questi giorni mi è capitato di dover lavorare su un nuovo progetto e di dover caricare le modifiche online man mano che il procedimento andava avanti... siccome farlo manualmente è un'operazione noiosa e ad alto rischio di errori (collegati all'ftp, carica le modifiche, elimina i files non più utilizzati...) ho pensato di sfruttare la potenza e la velocità di rsync agli hooks di GIT per effettuare questa operazione in automatico, ogni volta che faccio un push.
Puoi vedere il gist a questo indirizzo: Gist
Il funzionamento è molto semplice, eccolo riassunto:
#!/bin/sh ############## ## CONFIGURATION ############## # remote access sshUser="" sshPass="" remoteServer="192.168.1.1" remotePath="/var/www/production" # local database localDbName="myapp" # remote database remoteDdbUser="root" remoteDbPass="" remoteDbName="myapp" ############## ## WORKFLOW ############## # create a database backup and add it to the last commit (amend) mysqldump -uroot --skip-extended-insert $localDbName > database.sql git add database.sql git commit --amend --no-edit # since you can't force the password for SSH, echo it here as a hint (don't do this for critical projects! :)) echo When prompted, please insert this password: $sshPass # update all the files through rsync echo echo Updating files... rsync -rzhe ssh --delete --filter=':- .gitignore' ./ $sshUser@$remoteServer:$remotePath # update the database echo echo Updating database... cat database.sql | ssh $sshUser@$remoteServer "mysql -u$remoteDdbUser -p$remoteDbPass $remoteDbName" # and you're done! exit 0
Facile, no?
cookieBAR - una soluzione semplice per mettersi in regola con la cookie law
Nei giorni scorsi ho finalmente rilasciato la prima release pubblica di cookieBAR, una soluzione semplice per mettersi in regola con la cookie law europea. Se gestisci uno o più siti internet ma non conosci la cookie law ti converrà informarti in fretta, a luglio del 2015 diventerà obbligatorio adeguarsi alla normativa o le multe saranno decisamente salate:
7. Conseguenze del mancato rispetto della disciplina in materia di cookie.
Si ricorda che per il caso di omessa informativa o di informativa inidonea, ossia che non presenti gli elementi indicati, oltre che nelle previsioni di cui all'art. 13 del Codice, nel presente provvedimento, è prevista la sanzione amministrativa del pagamento di una somma da seimila a trentaseimila euro (art. 161 del Codice).
L'installazione di cookie sui terminali degli utenti in assenza del preventivo consenso degli stessi comporta, invece, la sanzione del pagamento di una somma da diecimila a centoventimila euro (art. 162, comma 2-bis, del Codice).
L'omessa o incompleta notificazione al Garante, infine, ai sensi di quanto previsto dall'art. 37, comma 1, lett. d), del Codice, è sanzionata con il pagamento di una somma da ventimila a centoventimila euro (art. 163 del Codice).
Per fortuna, la soluzione offerta da cookieBAR è estremamente semplice da adottare: è sufficiente inserire un tag <script /> da qualche parte nella pagina ed il gioco è fatto. È inoltre in preparazione anche un (altrettanto semplice) plugin per wordpress, che permette di effettuare le semplici operazioni di configurazione direttamente dal pannello di controllo.
Effettuare il deploy di un'applicazione Meteor.JS sul proprio server
Ho scoperto Meteor da poco e già me ne sono innamorato. Un'occhiata alla documentazione ed alle funzionalità penso sia sufficiente per capire le potenzialità di questa piattaforma quindi non intendo dilungarmi oltre. Passerò direttamente ad un aspetto successivo, cioè la pubblicazione di un'applicazione già fatta su un server raggiungibile dall'esterno, con un proprio indirizzo web (requisito necessario è avere accesso root SSH al sistema). Esistono due modi:
Metodo 1
Il primo metodo, quello più semplice e veloce, consiste nello sfruttare quello che meteor mette a disposizione cioè un hosting gratuito sui loro server, che può essere sfruttato utilizzando un sottodominio (es. ilmiosito.meteor.com) oppure, impostando i corretti parametri nel pannello di controllo del proprio hosting, con un dominio personale. Per caricare il sito è sufficiente posizionarsi nella directory di lavoro ed impartire questo comando:
meteor deploy ilmiosito.meteor.com
Et voilà. Nel giro di qualche secondo il sito è già online e funzionante a quell'indirizzo. Peccato che quell'hosting, per quanto comodo e gratuito, non sia proprio il massimo della velocità... ma niente paura c'è il
Metodo 2
Il secondo metodo consiste nell'ospitare l'applicazione su un proprio server (configurato con node.js e mongodb naturalmente). In questo caso il deploy è un decisamente più delicato e complesso, ma dopo aver sbattuto la testa in diversi modi credo di aver trovato la procedura corretta. Eccola:
Prima di tutto è necessario (o conveniente, giudicate voi in base al vostro grado di fiducia nel genere umano) configurare mongodb per non accettare le connessioni anonime. Procediamo quindi con la creazione di un utente di amministrazione su mongo:
$ mongo
MongoDB shell version: 2.6.5
​connecting to: test
> use admin
> db.createUser(
{
user: "amministratore",
pwd: "password",
roles:
[
{
role: "userAdminAnyDatabase",
db: "admin"
}
]
}
)
Fatto. Successivamente è necessario modificare il file /etc/mongodb.conf, decommentando la stringa auth=true per fare in modo che le connessioni a mongo non possano più avvenire in modo anonimo.
Fatto questo ci si ricollega a mongo con le credenziali appena inserite per creare il nuovo db:
$ mongo -u amministratore -p password --authenticationDatabase admin
> use ilmiodatabase
> db.createUser("ilmioutente", "lamiapassword")
Ok, anche questa è fatta. Abbiamo appena creato un nuovo database "ilmiodatabase" ed il relativo utente con accesso in lettura e scrittura.
Dopodiché vorremo importare il database che usavamo nella piattaforma di sviluppo, giusto? Per fare questo è sufficiente impartire questo comando (meteor deve essere avviato):
mongodump -h 127.0.0.1 --port 3001 -d meteor
Questo creerà una directory dump/meteor che contiene i files del database. Carichiamoli sul server tramite FTP o lo strumento preferito, e poi importiamoli:
mongorestore -h localhost --port 27017 -u ilmioutente -p lamiapassword -d ilmiodatabase cartella/dei/dump
Fatto? Bene, ormai ci siamo quasi. Ora passiamo ai files. Prima di tutto dobbiamo fare il build del sistema, quindi ci posizioniamo nella directory di sviluppo e diamo:
meteor build build
Questo comando creerà un pacchetto minifizzato, concatenato e quant'altro del nostro sito, mettendolo in formato compresso con tar.gz dentro la cartella "build". Ora possiamo prendere questo file, caricarlo sul server e scompattarlo. Fatto questo, è necessario installare le dipendenze di npm:
(cd programs/server && npm install)
A questo punto possiamo finalmente far partire il sito! Scherzavo :). Prima bisogna specificare i parametri di connessione. Questo passaggio è necessario ogni volta che si fa partire il server, ovviamente è possibile creare uno script di avvio per velocizzare questo passaggio:
export MONGO_URL='mongodb://ilmioutente:lamiapassword@localhost:27017/ilmiodatabase' export ROOT_URL='http://www.ilmiositoweb.ext' export PORT=3100
Ed infine...
node main.js
Et voilà! Il sito è ora raggiungibile all'indirizzo http://www.ilmiositoweb.ext:3100. Comodo vero? In effetti non molto, ma una volta capiti i passaggi non è poi una questione così complicata :)
Un'ultima cosa: probabilmente non è la scelta più comune quella di avere un dominio raggiungibile sulla porta 3100, ma è naturalmente possibile far girare il sito sulla normale porta 80 con alcuni trucchetti. Nel mio caso, avendo apache che occupa la porta 80 ho dovuto configurare un reverse proxy.
AGGIORNAMENTO
Siccome configurare un reverse proxy può non essere banale, aggiungo i passaggi che ho seguito per attivarlo (questo è molto utile in particolare se si vuole sfruttare la tecnologia del WebSocket, che con meteor è attiva di default).
Prima di tutto è necessario installare alcuni moduli di apache:
sudo a2enmod proxy proxy_http proxy_wstunnel
Poi bisogna creare un VirtualHost un po' personalizzato, che contiene la porta su cui risponde il server node ed il WebSocket:
<VirtualHost *:80 >
ServerAdmin postmaster@ilmiositoweb.ext
ServerName ilmiositoweb.ext
ServerAlias *.test.local
ServerSignature Off
ProxyRequests off
<Proxy *>
Order deny,allow
Allow from all
</Proxy>
<Location />
ProxyPass http://localhost:3101/
ProxyPassReverse http://localhost:3101/
</Location>
<IfModule mod_rewrite.c>
RewriteEngine on
RewriteCond %{HTTP:UPGRADE} ^WebSocket$ [NC]
RewriteCond %{HTTP:CONNECTION} ^Upgrade$ [NC]
RewriteRule .* ws://localhost:3101%{REQUEST_URI} [P]
</IfModule>
</VirtualHost>
Et voilà... con un riavvio del server apache dovrebbe essere tutto a posto!
AGGIORNAMENTO 2
Piccola precisazione: il metodo sopra indicato per attivare il websocket tramite proxy di apache funziona esclusivamente su apache 2.4 e successive versioni, mentre non è disponibile su apache 2.2 o precedenti. Nel caso in cui non sia possibile attivare websocket ma sia comunque necessario utilizzare il proxy potrebbe essere conveniente disattivare WS esportando questa regola prima di lanciare node:
export DISABLE_WEBSOCKETS=true
Personalizzare la shell bash quando si lavora su un progetto GIT
Per chi utilizza GIT da riga di comando può essere utile avere sottomano lo stato del proprio repository, per sapere al volo se ci sono dei file modificati mandare in stage, se c'è da farne il commit o se c'è qualcosa da pushare.

Per fortuna il file .bashrc ci viene in aiuto ed è (relativamente) semplice personalizzare la propria shell Bash secondo le nostre necessità. Nella fattispecie, ho optato per indicare in rosso fra parentesi graffe il nome del branch attivo in cui sono presenti files modificati non ancora mandati in stage, in giallo (sempre fra graffe) i files in stage di cui fare il commit, mentre in verde (fra parentesi tonde) i repository puliti, con un asterisco ad indicare se è necessario fare il push fra il repository locale e quello remoto. In azzurro, infine, i repository che contengono untracked files.
Dopo un po' di utilizzo sono soddisfatto del risultato, è comodo avere quelle informazioni a portata di mano senza dover fare git status ogni volta.
Se vuoi implementare anche tu questa modifica, segui le istruzioni che trovi qua (https://github.com/ToX82/git-bashrc).
Facile, no?
Aruba e "No input file specified."
 Lavoro nel campo dello sviluppo web da quasi un decennio ormai, eppure alcuni hosting continuano a stupirmi ogni volta che ho a che fare con loro. Uno di questi è aruba, che con il suo pannello di controllo che sembra arrivare dagli anni 90 continua a mettermi in difficoltà fin dalla prima volta che l'ho conosciuto.
Lavoro nel campo dello sviluppo web da quasi un decennio ormai, eppure alcuni hosting continuano a stupirmi ogni volta che ho a che fare con loro. Uno di questi è aruba, che con il suo pannello di controllo che sembra arrivare dagli anni 90 continua a mettermi in difficoltà fin dalla prima volta che l'ho conosciuto.
Questa volta si è trattato del sito di un cliente, online da alcuni anni, che in questi giorni ha deciso di spostare il tutto su aruba. Di solito è sufficiente trasferire file e database, modificare un file di configurazione, svuotare la cache ed il gioco è fatto ma stavolta mi sono imbattuto in un errore strano: L'home page funzionava perfettamente ma tutte le altre pagine mostravano un triste messaggio "No input file specified.", nero su bianco. Impenetrabile come la nebbia della bassa padana.
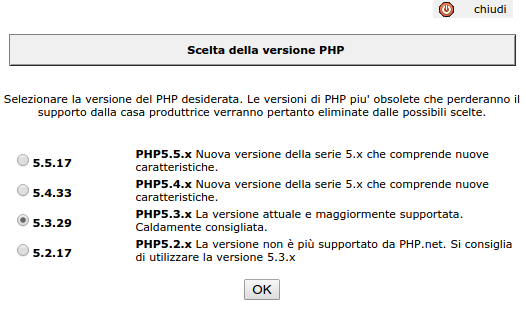
Dopo interminabili ricerche su internet, una (inutile) ri-esecuzione della copia di file e database, qualche momento di stupore nello scoprire che è "caldamente consigliata" la versione 5.3.29 di PHP ("PHP5.3.x La versione attuale e maggiormente supportata. Caldamente consigliata." il cui supporto è terminato mesi fa) e che la versione 5.4 (uscita nel 2012) è considerata la "Nuova versione della serie 5.x che comprende nuove caratteristiche", eccetera... finalmente ho capito il problema. Il file php.ini di default su aruba contiene un'istruzione cgi.fix_pathinfo = 0 che su alcuni siti (per esempio joomla, o nelle versioni vecchie di CakePHP) può dare problemi.
Per risolvere questa scocciatura è sufficiente andare nel "magnifico" pannello di controllo, cercare (navigando fra le mille finestre che aruba gentilmente ci propone) la voce Personalizzazione del file PHP.INI ed all'interno di quella nuova finestra selezionare cgi.fix_pathinfo, che imposta il relativo valore a 1.
Fatto questo, dovrebbe tornare tutto a funzionare. O almeno si spera...